Warning
This article is WIP. It is 90% completed.
In this article we will be implementing from scratch the UDP Tracker protocol for BitTorrent. You will:
- Build a highly concurrent application without fancy external libraries (e.g. Akka, Vert.x, Monix), but rather by leveraging more fundamental concurrency building blocks.
- Understand the UDP protocol and its interface in Java/Scala.
- Use
AtomicReference‘s to manage state across several threads. - Use
Future/Promise(in Scala) andCompletableFuture(in Java) to deal with concurrency.
The focus of Concurrency Deep Dives is concurrency. On other articles of this project, I try to understand it at deeper level by studying the theory, learn the primitives and how these are used to build higher level abstractions. The best way to cement knowledge is to apply it, so in this article I will be building code that interacts with a Tracker on a BitTorrent network. You will have to understand the problem formulation, so you need to read 5 minutes about BitTorrent, UDP, and the UDP Tracker protocol which is a subset of the BitTorrent protocol.
You can skip these contextualization sections, and jump right to the implementation to see concurrency concepts being applied to real problems.
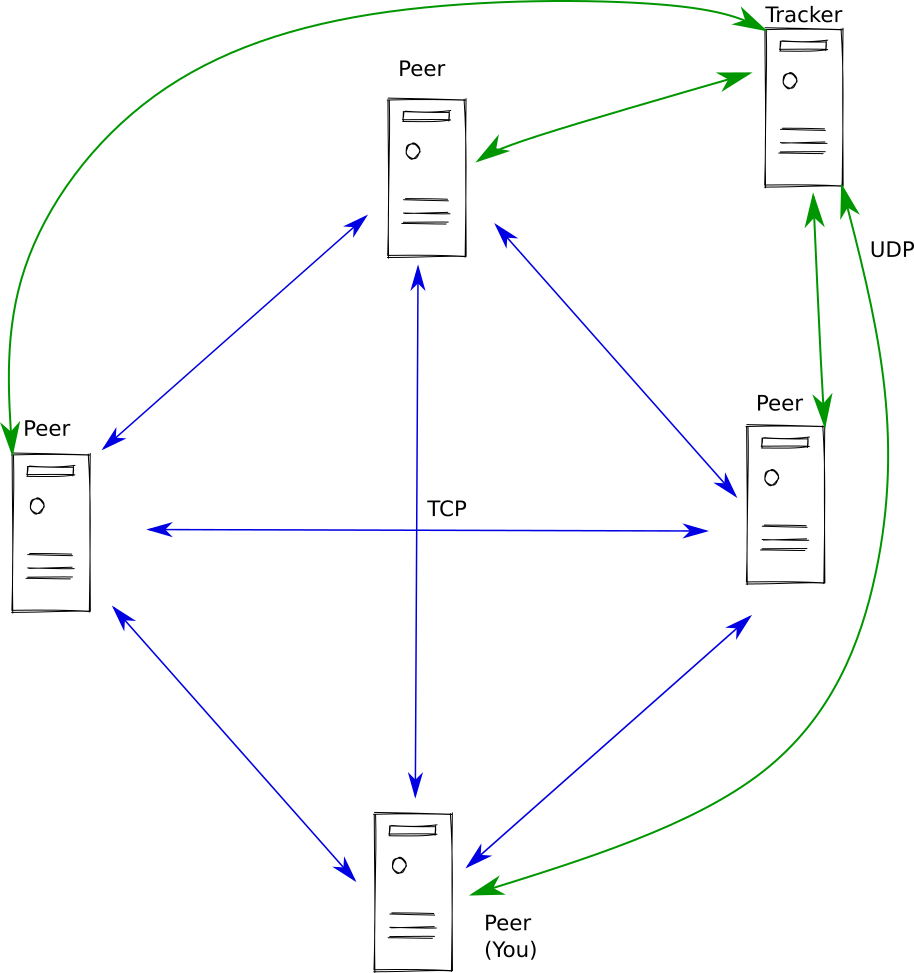
BitTorrent
The BitTorrent I am referring to is the famous peer-to-peer (P2P) protocol widely used in the 2000s for file sharing. It was invented by a man called Bram Cohen and widely used to pirate movies, music, and other copyrighted content. By 2005 it was responsible for over 35% of Internet traffic. Since then, its “share” of the Internet decreased to the low digits.
Despite what many believe, BitTorrent is not originally completely decentralized. Before the download of a (torrent) file occurs via a Peer-to-Peer (P2P) network, the torrent client needs to know the network socket addresses of other peers in the network that have a subset of the file. The torrent client can request the set of such peers for a torrent from a Tracker. The Tracker is a server. A centralized part of system where all peers (i.e. clients) for a particular torrent register to join the network. Each client knows how to contact the tracker (or trackers) for a given torrent as the socket address is contained within the .torrent file itself.
Clients communicate with Trackers via the UDP tracker protocol, which, as the name suggests is layered on top of UDP.
This was so originally. In 2008, the DHT protocol proposal appeared (BEP 5), which allows for trackerless torrents. The centralized Tracker entity disappears, and every torrent client becomes a tracker. The BitTorrent protocol then becomes truly distributed. This DHT protocol has since been implemented by most BitTorrent clients (e.g. Transmission, Azure, Deluge, µTorrent).
We want to write some code in Java/Scala code that can interact and extract the information from trackers; namely, we want the socket addresses of the other peers in the system that contain the file we are also interested in. In other words, we want to implement a subset of the functionality of full-blown mainstream BitTorrent client (e.g. μTorrent, Transmission, Vuze).
Because this happens via UDP, you must have basic understanding of it.
UDP
UDP in general
UDP is part of the TCP/IP set of protocols. It’s the 2nd transport layer protocol, the other being TCP. UDP provides much fewer features than TCP, and is much, much simpler to understand.
Historically, the features of the TCP and IP protocols were bundled together. The creators realized that some applications might not need the full power provided by such protocol, as that power comes at a cost. They decided to split that original protocol into what is now known as TCP and IP, and then added the extra protocol UDP for those applications that did not require TCP and didn’t want to pay its overhead.
UDP is a wrapper protocol around IP. It provides little extra features on top of it. Mostly just virtual socket addressing. That is, it provides the abstraction of socket ports, the same way TCP does. As in, a UDP (or TCP) socket address is the IP of the host plus a port number (e.g. 93.158.213.92:1337).
Note
UDP is one of the simplest protocols on the internet. It is a wrapper protocol. It provides almost no functionality on top of IP. Like TCP, it does provide multiplexing via virtual ports. That is, many applications might be using UDP on a host, each on its own port. The combination of ip address and a port is what we know as a socket.
Here is a list of the characteristics of UDP:
- Faster than TCP, as it has less overhead.
- Sends and receives stand-alone messages (rather than the stream API in TCP)
- No guarantee of delivery of those messages.
- If a message does arrive however, it arrives intact, not corrupted.
- Message boundaries are preserved.
- A single message received corresponds to a single message sent (in contrast with TCP, as it models a stream).
- Messages can be re-ordered (TCP guarantees ordering).
- No connection is established between the 2 hosts (TCP does).
- The same UDP socket can be used to send and receive messages from multiple UDP ports simultaneously. In TCP, a socket is associated with a connection to a single remote host.
Unlike TCP, there is no distinct server or client. From the view of UDP, both are equal peers. Off course, from the point of view of the application that relies on UDP there can still be a conceptual server/client relationship.
Important
Applications that rely on UDP are responsible themselves to take care of reliability and retransmission issues.
Note
The motivation for BitTorrent protocol to use UDP for the tracker is to reduce traffic on these servers. Trackers are a centralized “entity” in the BitTorrent’s quasi-decentralized world, and have to serve many peers. Going with UDP allows a saving of 50% of traffic compared with HTTP (which was the original solution and uses TCP).
UDP in Java/Scala
TCP and UDP are protocols which are implemented by the operating system (OS) of the host. Java and the JVM simply provide classes that interface with the OS. This is true of other languages. For both, the classes are divided into blocking and non-blocking, which again mirror the functionality provided by the OS.
The blocking means the client code will block the calling tread until there is data available. This is bad. Ultimately this means that large servers have to have a thread for each TCP connection, which doesn’t scale. That is, the more TCP connections you have, the more threads you need, and because threads carry a cost, you are limited by your resources.
Non-blocking allows client to use much fewer threads than sockets. It allows multiplexing where 1 thread can handle many TCP socket connections. Meaning you don’t need to create more threads, and save resources. Ultimately, this means that the same machine can serve many more TCP connections.
| TCP | UDP | |
|---|---|---|
| Blocking | new java.net.Socket(…) new java.net.ServerSocket(…) | new java.net.DatagramSocket() |
| Non-blocking | java.nio.channels.SocketChannel.open() java.nio.channels.ServerSocketChannel.open() java.nio.channels.Selector.open() | java.nio.channels.DatagramChannel.open() java.nio.channels.Selector.open() |
class DatagramPacket {
// Constructs a datagram packet for sending packets of length length to the specified
// socket address (IP+port number). The length argument must be less than or equal to buf.length.
public DatagramPacket(byte buf[], int length, SocketAddress address) {}
// Constructs a datagram packet for receiving packets of length length.
public DatagramPacket(byte buf[], int length) {}
// Returns the length of the data to be sent or the length of the data received.
public int getLength() {}
// Returns the buffer of the data received or sent. Depending on how the instance is being used.
public byte[] getData() {}
// other less important methods
}Importantly, notice that every datagram received from a datagram socket contains the IP address and port number of the host that sent that message.
Because same socket on the client may be used to send and receive UDP packets to multiple different remote UDP sockets, an received DatagramPacket contains the source of the packet (IP+port).
UDP Tracker protocol
The initial summary of BitTorrent, is too superficial to know what we actually need to design.
The UDP Tracker protocol is the subset of the BitTorrent protocol governing the “discovery” of the peers of a P2P network. It relies on the UDP protocol for their tracker. A tracker is a server that enables a Bittorrent client to find other peers of the network (also called swarm) that it can ask portions of the torrent file from.
The trackers are a centralized component of this semi-centralized protocol. They are servers that store and distribute what are the peers downloading a torrent file. Each Bittorrent client only requests the trackers for the peers, and then downloads the torrent file from the peers.
But where does one find the addresses of these trackers to begin with?
In the torrents themselves. As you likely known, torrents are associated with a .torrent file that is referred to as “the torrent”. This metadata file contains a sequence of tracker socket addresses. These are value of the key announce and announceList of the torrent metadata file:
The contents of a torrent file
Torrent
announce: udp://tracker.leechers-paradise.org:6969/announce
info
Multi-File
dirName: The.Guardians.of.the.Galaxy.Holiday.Special.2022.720p.WEBRip.400MB.x264-GalaxyRG[TGx]
files:
File: Holiday updates.txt
Size: 175
File: The.Guardians.of.the.Galaxy.Holiday.Special.2022.720p.WEBRip.400MB.x264-GalaxyRG.mkv
Size: 418227626
File: [TGx]Downloaded from torrentgalaxy.to .txt
Size: 718
pieceLength: 262144
pieces:
[
674f5302cb1db877ba06fea9472c05fbdfc7c824,
8412eaced24eaaba6af4f76c643190726f4f2ff9
][showing 2/1596]
announceList:
udp://tracker.leechers-paradise.org:6969/announce
udp://tracker.internetwarriors.net:1337/announce
udp://tracker.opentrackr.org:1337/announce
udp://tracker.coppersurfer.tk:6969/announce
udp://tracker.pirateparty.gr:6969/announce
udp://9.rarbg.to:2730/announce
udp://9.rarbg.to:2710/announce
udp://bt.xxx-tracker.com:2710/announce
udp://tracker.cyberia.is:6969/announce
udp://retracker.lanta-net.ru:2710/announce
udp://9.rarbg.to:2770/announce
udp://9.rarbg.me:2730/announce
udp://eddie4.nl:6969/announce
udp://tracker.mg64.net:6969/announce
udp://open.demonii.si:1337/announce
udp://tracker.zer0day.to:1337/announce
udp://tracker.tiny-vps.com:6969/announce
udp://ipv6.tracker.harry.lu:80/announce
udp://9.rarbg.me:2740/announce
udp://9.rarbg.me:2770/announce
udp://denis.stalker.upeer.me:6969/announce
udp://tracker.port443.xyz:6969/announce
udp://tracker.moeking.me:6969/announce
udp://exodus.desync.com:6969/announce
udp://9.rarbg.to:2740/announce
udp://9.rarbg.to:2720/announce
udp://tracker.justseed.it:1337/announce
udp://tracker.torrent.eu.org:451/announce
udp://ipv4.tracker.harry.lu:80/announce
udp://tracker.open-internet.nl:6969/announce
udp://torrentclub.tech:6969/announce
udp://open.stealth.si:80/announce
http://tracker.tfile.co:80/announceThe tracker service is provided over a simple protocol over UDP.
The protocol is composed of only 2 pairs of request/response messages, totalling 4 distinct. These will correspond to 4 UDP packets/datagrams/messages.
Note that every single mainstream torrent client out there (e.g. Transmission, Deluge) must implement this logic.
protocol id: 8 bytes integer // always the magic number 0x41727101980
action: 4 bytes integer // should be 0
transaction id: 4 bytes integer // randomly generated. Important. Used to match request with responseaction: 4 bytes integer // should match the 0 of the request
transaction id: 4 bytes integer // should match a transaction id of the request
connection id: 8 bytes integer // random id generated by the tracker. identifies a connectionconnection id: 8 bytes integer // a valid connection id received from a previous connection request/response pair
action: 4 bytes integer // should be 1
transaction id: 4 bytes integer // randomly generated id used to match with a future announce response
info hash: 20 bytes // sha-1 hash of the torrent file contents which identifies the torrent uniquely
downloaded: 8 bytes integer // informs the tracker how much of the torrent file you have already downloaded. Used for statistics
left: 8 bytes integer // informs the tracker how much of the torrent file you have still need to download. Used for statistics.
uploaded: 8 bytes integer // informs the tracker how much of the torrent file you have uploaded to other peers. Used for statistics.
event: 4 bytes integer //
ip address: 4 bytes // your ip address. usefull in case of proxies
key: 4 bytes integer //
number peers wanted: 4 bytes integer // number of peers of the swarm that the tracker will return on the response
port: 2 bytes integer // the socket port number where the clientaction: 4 bytes integer // should be 1
transaction id: 4 bytes integer // should be 0
interval: 4 bytes integer // randomly generated
leechers: 4 bytes integer
seeders: 4 bytes integer
peers: multiple of 6 bytes // for each, the 1st 4 are the IP, and the remaining 2 the port numberThis is not enough. Even if we can match incoming messages to their respective sender, within the same tracker, messages might have been dropped or re-ordered. For that reason, UDP based protocols generally obtain some reliability by sequence-numbering th outgoing packets. The receiving end can then attach that number to the corresponding reply, so that the other peer can match the request/response. This is done by the “Tracker protocol” of BitTorrent.
Problem statement
The code to be implemented must be able to communicate simultaneously with many tracker servers. How many? A real BitTorrent client supports downloading multiple torrents, each of which interacts with many tracker servers. So thousands at least. This means the problem is highly concurrent, which is why it is meaningful in the first place for us students of concurrency.
If we were just to code the interaction with a single tracker, it would be easier and even less interesting. We could just send a request and wait for the response on the calling thread.
We will design a class that is responsible for communicating with all trackers across all torrents, rather than having one instance responsible for a single torrent. In other words, there will be only one single entity/instance responsible for all “tracker” functionality across the entire system. The interface could look like:
import java.net.InetSocketAddress;
import java.util.List;
import java.util.Set;
public interface Tracker {
// InfoHash is the SHA-1 hash of a .torrent file. It is central in the BitTorrent world
// as it allows torrents to be uniquely identified. For clarity, I represent it
// as a specific type, but regard it as an alias for a String.
public void submit(InfoHash torrent, List<InetSocketAddress> trackers);
public Set<InetSocketAddress> peers(String torrent);
}Whereby, for every torrent to be downloaded there will be a call to submit, and then later, there are multiple calls to peers to obtain the peers of the network for that torrent. This suggests that the Tracker implementations will have to maintain state; they will keep a set of peer socket addresses for each torrent submitted; implementations will have to be thread safe, as its methods might be called from different threads.
Note that separate calls to peers will likely return different results; some peers of a swarm/torrent network disconnect after some time, new peers join the network (i.e. a user opened a BitTorrent client on their computer and started downloading a torrent), or maybe the tracker just didn’t send the full list of peers it had on a previous request. Not to mention we are multiplexing over all the trackers for a torrent. So the result will depend on which peers have returned by the time the call is made.
Note
Instead of having two methods, whereby the clients need to call peers to retrieve the peers, a better abstraction would be to return a stream for method submit. For example a Rx Java stream, or, in the case of Scala, a Monix Observable.
Returning a future value would not be a good fit. There are many trackers associated with a torrent, so we would have to decide when to complete the future. Waiting for all trackers to return the peers might take a long time, but completing the future as soon as the first tracker returns the peers would exclude the peers from all other trackers. This exemplifies the paradigm difference between future/promises, which are an abstraction for a single value, and streams, which model a flow of values.
The goal for the remainder of the article is to implement the interface Tracker abstraction.
We start by observing this is a stateful problem; conceptually the state is Map[InfoHash, Map[InetSocketAddress, TrackerState]], where InetSocketAddress is the socket address of a single tracker, and TrackerState is yet to be defined but represents the state of the communication with that tracker; potentially holding the peers retrieved from it. Any implementation goal, this or other, must ultimately manage that state.
Before we dwelve further, we have to address how many socket objects we have in the system. This is a topic that affects any implementation, regardless of the concurrency model we choose (e.g. actors, futures).
Sockets
We have to communicate with each tracker via UDP. From UDP in Java/Scala, this is exposed via instances of class java.net.DatagramSocket, or java.net.DatagramChannel.
But do we have one distinct instance of java.net.DatagramSocket to send and receive UDP messages for each tracker, or is it possible to have a single one instance multiplexing across all trackers?
With TCP there would be no choice; a java.net.Socket would require one separate instance for each tracker. TCP is a connection oriented protocol; the connection existing between two sockets. This fact transpires onto the API exposed by Java whereby each socket instance is associated with one single remote host/socket, and after the instance is created, it can neither send nor receive data from other sockets.
UDP is fundamentally different and presents a choice. It is connectionless and each message is independent of any other. In fact, each message sent must contain the socket address of the destination. So a single instance of java.net.DatagramSocket can send messages to multiple sockets. It can also receive from multiple.
Why is this important for concurrency?
A socket instance per remote socket address – that is, a distinct java.net.DatagramSocket object to communicate with each tracker – would lead to as many threads as there are trackers. This is because these are blocking IO “mediums”. By blocking I mean that java.net.DatagramSocket#read() blocks the calling thread until there is something available. So if you have a single thread responsible for reading data from multiple sockets than if one blocks because no data is available, the other sockets would not be read, which would result in slowness and loss of data:
import com.google.common.collect.ImmutableList;
import com.google.common.collect.ImmutableMap;
import com.google.common.collect.ImmutableSet;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetSocketAddress;
import java.util.Map;
public class BadTracker implements TrackerJava {
ImmutableMap<InetSocketAddress, DatagramSocket> sockets;
final int packetSize = 65507;
public BadTracker(ImmutableMap<InetSocketAddress, DatagramSocket> sockets) {
this.sockets = sockets;
Thread thread = new Thread(new ReadMessagesFromSockets(), "ProcessingThread");
thread.start();
}
@Override
public void submit(InfoHash torrent, ImmutableList<InetSocketAddress> trackers) {}
@Override
public ImmutableSet<InetSocketAddress> peers(InfoHash torrent) {}
// This class is a Runnable which will become a thread of execution.
private class ReadMessagesFromSockets implements Runnable {
@Override
public void run() {
while (true) {
// Looping around each and every socket address/socket pair
// which represents each tracker.
for (Map.Entry<InetSocketAddress, DatagramSocket> tracker : sockets.entrySet()) {
DatagramPacket packet = new DatagramPacket(new byte[packetSize], packetSize);
InetSocketAddress trackerSocketAddress = tracker.getKey();
DatagramSocket trackerSocket = tracker.getValue();
// This call blocks until there are packets available. The thread is de-scheduled,
// and no other sockets are read even if they have data available.
trackerSocket.receive(packet);
process(packet);
}
}
}
}
}From above, if there was nothing to read from the network for a particular socket, the thread would halt at socket.receive() preventing the packets from other sockets to be read and processed in a timely manner; if the other sockets are seeing a lot of activity, after some buffering the underlying operating system would discard UDP packets, and they would also be lost for the application. That being said, UDP protocol applications should expect packets to be lost regardless, but you see how this is not ideal.
We could use
import java.net.DatagramSocket
val udpSocket = new DatagramSocket()
udpSocket.setSoTimeout(???)which sets a limit to the amount of time a thread waits for a packet before “waking up” and throwing an exception.
But then you have to deal with the dilemma of how to size the timeout. Too big, and you lose responsiveness and data; too small and you waste resources. For context, if you choose a value of 50 ms, then if you loop over 10000 trackers/sockets, the next packet of the last socket would only be processed some 500 ms (~ 8 min) after.
All this to say that you would need one thread per socket. And that is a problem. Threads have a cost. Each consumes memory, and switching between them takes CPU cycles. So if your number of threads grows linearly with the number of trackers in the system, you would consume too much memory. Meaning the system is less scalable.
Important
Be sure to know what I mean by socket. It depends on the context. It normally refers to the language independent and network concept of an IP address plus port number which uniquely identifies a TCP or UDP application running on a host. This is independent of any programming language. At the same time, InetSocketAddress is the class in the Java world which represents this concept. Finally, java.net.Socket, and java.net.DatagramSocket are also Java classes that Java/Scala programmers have at their disposal enabling them to communicate with hosts via the TCP and UDP protocols respectively. Confusingly, I often refer to instances/objects of these classes also as sockets. However, when there is ambiguity, I use the term socket address for the former concept.
For these reasons, we will have a single DatagramSocket sending and receiving packets to and from all possible trackers in our system. As an important side note, if this were TCP, then to achieve 1 thread serving multiple (TCP) sockets, we would need channels and a selector as summarized on table Classes in Java/Scala for networking.. Fortunately, UDP is fundamentally different, and this multiplexing which in TCP is only possible via channels/selectors can be done by the blocking version. In other words, there isn’t much added benefit of non-blocking UDP sockets (i.e. DatagramChannel).
import java.net.DatagramSocket;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.Set;
import java.util.concurrent.atomic.AtomicReference;
public class TrackerImpl implements Tracker {
DatagramSocket socket;
AtomicReference<ImmutableMap<InfoHash, ImmutableMap<InetSocketAddress, TrackerState>>> sharedState;
public TrackerImpl() throws SocketException {
this.socket = new DatagramSocket(config.port);
this.sharedState = new AtomicReference<ImmutableMap<InfoHash, State>>(ImmutableMap.of());
}
@Override
public void submit(InfoHash torrent, ImmutableList<InetSocketAddress> trackers) {}
@Override
public ImmutableSet<InetSocketAddress> peers(InfoHash torrent){}
}The TrackerImpl will be responsible for communicating will all BitTorrent trackers across many torrents. Its responsibility is simple. For every torrent (i.e. infohash) submitted to it, it must communicate with all its trackers to ultimately obtain a list of peers (for that torrent) which will be accessed by method peers.
It’s important to understand that our single DatagramSocket instance (the socket) will send and receive ALL UDP requests across all trackers. This is a stark difference to TCP which requires a distinct socket object for every pair (local+remote) of sockets. Again, UDP is stateless, not connection based like TCP.
The reader thread
We already have some information restricting how our system will look like:
- Two interface methods we have to implement.
- A single udp socket.
- Some mutable state for each tracker, representing the communication stage and possibly the returned peers.
There are many ways to go about this problem. This is a highly concurrent problem because we want to interact with many trackers simultaneously.
A good fit would be to use Akka actors. The actor concurrency model with one actor per tracker would be intuitive. Obviously I don’t want to go with Akka as the whole point is to understand concurrency primitives. However, I do briefly summarize what a solution could look like further down.
Regardless of the approach, we will likely always have one single thread dedicated to reading packets from the (only) socket. Even with actors, we would still want just one udp socket in the system, and only one thread reading from it.
This single thread is responsible for reading all UDP packets across all trackers. That thread has a very concise role:
- Read a UDP packet from the socket.
- Deserialize the packet into a valid BitTorrent Tracker message.
- Determine if it comes from a known tracker, and if the message matches the current state of that tracker.
- Perform some quick, non-blocking, action. For example:
- Send a message to an actor in the actor approach.
- Mutate shared state directly.
- Complete a future, add element to a stream.
- Repeat indefinitely.
We can encapsulate this behaviour in a class. We make it private as not to leak implementation details; client code doesn’t need access to it. We will spawn a single thread that runs this class whenever we create an instance of Tracker.
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.util.Map;
import java.util.concurrent.atomic.AtomicReference;
import com.google.common.collect.ImmutableMap;
final class ReaderThread implements Runnable {
final DatagramSocket udpSocket;
final AtomicReference<ImmutableMap<InfoHash, ImmutableMap<InetSocketAddress, TrackerState>>>
theSharedState;
final int packetSize = 65507;
public ReaderThread(
DatagramSocket udpSocket,
AtomicReference<ImmutableMap<InfoHash, ImmutableMap<InetSocketAddress, TrackerState>>>
sharedState) {
this.udpSocket = udpSocket;
this.theSharedState = sharedState;
}
@Override
public void run() {
while (true) {
DatagramPacket dg = new DatagramPacket(new byte[packetSize], packetSize);
try {
udpSocket.receive(dg);
} catch (IOException e) {
throw new RuntimeException(e);
}
process(dg);
}
}
}Method process needs to be fast. Taking too long prevents other packets from being processed. If the buffers in the underlying operating system fill up, the packets are discarded.
Critically, udpSocket.receive will populate the packet with the origin socket address (i.e. IP + port). This allows process to match that against the current state.
Note
Why do we create a byte array of length 65507 bytes to accommodate the incoming datagram packet?
Because that is the maximum payload any udp packet can have. So we are sure not to miss any data. We are always safe. Arguably, we could use insight of the Tracker protocol to restrict this further.
The state of each tracker
The type TrackerState used in the past snippets hasn’t been defined yet.
According to UDP Tracker protocol earlier, it is reasonable to model all possible state of each tracker as:
public sealed interface TrackerState {
record ConnectSent(int txdId) implements TrackerState {}
record ConnectReceived(long connectionId) implements TrackerState {}
record AnnounceSent(int txnId, long connectionId) implements TrackerState {}
record AnnounceReceived(long timestamp, int numPeers) implements TrackerState {}
}Important
It is easy to confuse the classes representing the messages defined by the UDP Tracker protocol with the classes representing the state, although they are closely related as the state changes occur as a consequence of sending or receiving the messages and vice-versa.
The messages sent and received on the wire for each tracker are: connection request, connection response, announce request, and announce response. We enumerated them at UDP Tracker protocol, but we have not shown the data classes representing them in Java/Scala for brevity.
On the other hand, the data classes representing the application state for a given tracker were shown above:
- ConnectSent
- ConnectReceived
- AnnounceSent
- AnnounceReceived
I ended up removing the state ConnectReceived. In the following implementation we will be sending an announce request immediately after receiving a connect response, so there was no value in modelling the state in between. The state can jump from ConnectSent to AnnounceSent directly.
The objective is to get the state of each tracker to AnnounceReceived.
For each tracker, the main features defined by the protocol are:
- Resend a connection request if no connection response arrives in time.
- Resend an announce request if no announce response arrives in time.
- Timeout a connection id, and re-connect after the 60 seconds the protocol defines as being the limit.
How to do this? We have already decided that the reader thread’s only responsibility will be actively listening for incoming udp packers and possibly altering the shared state in accordance.
Using Akka 👎
If we were using a concurrency framework like Akka actors (which exists in both java and scala), our problem would be simpler. But like me, you probably want to learn more of the fundamentals, and less about 3rd party frameworks developed by people who themselves master the fundamentals and had a great time doing the creative work.
But for the sake of comparison, how could we use Akka actors?
We could have an actor class representing the communication with a single tracker. This actor would be responsible for the actual protocol logic: sending the necessary requests and processing the responses, implementing timeouts and the re-try feature of UDP packets, re-connecting when a connection expires. The actor would also contain and manage the TrackerState.
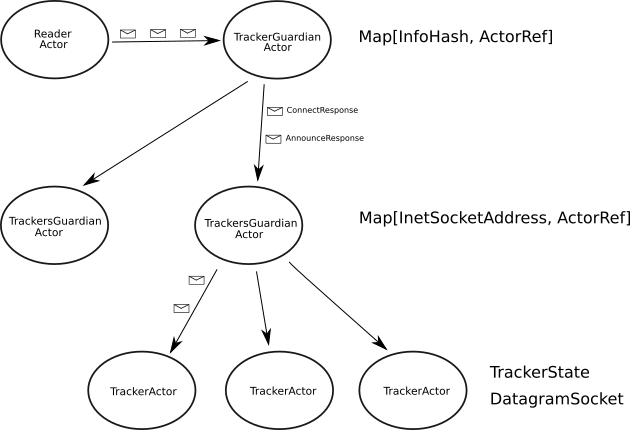
In this approach, we still have only one shared DatagramSocket instance multiplexing over all trackers. You could argue that as we have as many actors as trackers, creating a DatagramSocket for each tracker actor, responsible for sending and receiving packets to and from that tracker is more elegant and more decoupled.
We can’t do that though, as you can’t (or rather shouldn’t) have blocking calls inside an actor. Calling udpSocket.receive(<some-datagram>) blocks the thread where the actor is running. Because all tracker actors would be reading from their respective socket, and critically, because the core philosophy of the actor model is to have a relatively small number of threads handling many actors, the actor system’s infrastructure would starve. We would run out of threads for the actor system, as they would all be assigned to those actors reading from the sockets which are making no progress as they are waiting for data from the socket.
Rather, we still use only one datagram socket instance, which is shared across all instances of the tracker actors and also by the “reader actor” which has the same logic as the reader thread. Obviously the reader actor blocks, but that is fine, as there is only one such actor in the entire system. Then, this “reader actor” would send the received messages to the top level actor which would route it to the appropriate tracker actor.
This model is very intuitive. All the communication with a tracker is done under the actor, and that’s all the actor does too. The actor only has access to its TrackerState which is thread-safe by default, which frees us from thinking about synchronization of shared data.
Using Futures 👍
Instead, we are going to use futures, which are less powerful but closer to concurrency principles. How futures work internally is left for another post, but it is important to emphasize that futures are not a native concept in Java/Scala. You can design them from scratch using more fundamental building blocks. The teaser for a future article is: a future is just an atomic reference protecting a sequence of callbacks which are submitted to run on a thread-pool once the original future completes.
Instead of having an Akka actor per tracker, we will have a future also per tracker. Using futures is less intuitive, not least because the state is shared, and we have to explicitly protect access to it. Also, the “logic” steps of communication with each tracker is spread over a few different methods rather than bundled together on a cohesive actor class.
We will have as many futures as you would have had actors. This is appropriate in this case, but not possible in general, as actors are much more powerful than futures. They allow bidirectional communication between threads whilst futures only allow in one direction.
The outline of the implementation is:
public class TrackerImpl implements Tracker {
DatagramSocket socket;
AtomicReference<ImmutableMap<InfoHash, State>> sharedState;
Executor ex;
public TrackerImpl(Config config, Executor ex) {
this.socket = new DatagramSocket(config.port);
this.sharedState = new AtomicReference<ImmutableMap<InfoHash, State>>(ImmutableMap.of());
this.ex = ex;
Thread readerThread =
new Thread(new TrackerReader(this.socket, this.sharedState), "ReaderThread");
readerThread.start();
}
@Override
public void submit(InfoHash torrent, ImmutableList<InetSocketAddress> trackers) {
for (InetSocketAddress tracker : trackers) {
run(torrent, tracker)
.thenApplyAsync(res -> null)
.exceptionally(error -> null);
}
}
private CompletableFuture<Void> run(InfoHash torrent, InetSocketAddress tracker) {
return connect(torrent, tracker, 0)
.thenComposeAsync(
connectResponseAndTimestamp -> {
Connection connection =
new Connection(
connectResponseAndTimestamp.getValue0().connectionId(),
connectResponseAndTimestamp.getValue1());
return announce(torrent, tracker, connection, 0)
.thenComposeAsync(
announceResponse ->
setAndReannounce(
torrent, tracker, announceResponse.peersJava(), connection),
ex);
},
ex)
.exceptionallyComposeAsync(
error -> {
if (error instanceof CompletionException) {
Throwable cause = error.getCause();
if (cause instanceof TimeoutException) {
return run(torrent, tracker);
} else return CompletableFuture.failedFuture(cause);
} else return CompletableFuture.failedFuture(error);
});
}
CompletableFuture<Pair<ConnectResponse, Long>> connect(
InfoHash torrent, InetSocketAddress tracker, int n) {}
CompletableFuture<AnnounceResponse> announce(
InfoHash torrent, InetSocketAddress tracker, Connection connection, int n) {}
CompletableFuture<Void> setAndReannounce(
InfoHash torrent,
InetSocketAddress tracker,
ImmutableSet<InetSocketAddress> peers,
Connection connection) {}
}On the following sections we will go through implementing connect, announce, and re-announce.
First, method run is applied over all trackers of the torrent, so the map operation will return Set[Future[Unit]]. Each element of the set is a future corresponding to a tracker.
Why does each future return Unit/void rather than the socket addresses (e.g. Set[InetSocketAddress]) corresponding to the peers? Because we would then not know how to “join” all such futures. This goes back to the earlier discussion about the API. We wouldn’t know how to convert Set[Future[Set[InetSocketAddress]]] into Future[Set[InetSocketAddress]]. We would either risk waiting an unbounded amount of time until all futures complete or compromise and return a subset of peers.
Instead, we keep shared state which is returned on calls to peers. This state is updated concurrently as soon as each tracker returns its peers; as soon as we have the list of peer addresses from the first tracker, those addresses will be visible via a call to peers.
This shared state is updated as a side effect of running methods connect, announce, and re-announce.
Each tracker will be associated with one future. This future is a facade for a sequence of computations which together implement the UDP Tracker protocol for a single tracker:
- Connecting
- Sending request.
- Waiting for the response
- Resending after timeout according to protocol.
- Announcing
- Sending request
- Waiting for the response
- Resending after timeout according to protocol.
- If connection expires, going back to point 1.
- Re-Announcing
- Sending a new announce request for new set of peers.
- Protocol defines we should keep asking for peers, as these are not static.
- If connection expires, going back to point 1.
- Keep re-announcing indefinitely at some frequency.
These 3 steps correspond to the methods connect, announce, and re-announce. For each tracker, each step only begins after the previous has completed. However, the overall future returned by run will never complete. Or rather, it will complete only when there is an error; as it loops over these steps it updates the shared state accordingly, namely with new peers.
That it never completes in not a problem, as we don’t publish the future value. The client code never gets a reference to it.
Notice also we create the reader thread in the background as when we create a tracker instance. Even though the udp messages to the trackers will be sent from the TrackerImpl, they will be processed by this reader thread.
As discussed below, ultimately it is the reader thread which will complete the futures returned by connect, announce, and re-announce.
TODO: Talk about many futures flying around. Use that diagram with overall design ?
AtomicReference
We haven’t yet discussed how to protect the shared state from concurrent access.
Conceptually, the state is the nested map Map[InfoHash, Map[InetSocketAddress, TrackerState]], and as suggested by Layout of the approach with futures, the “steps” for each torrent (i.e. InfoHash) and for each tracker within that torrent will run concurrently on the threads of executors. As we will see later, each such “step” will need to change the data.
It is therefore essential to synchronize access to it. The most conventional approaches would be:
ConcurrentHashMap- Java intrinsic locks (i.e. monitor locks with
synchronized) AtomicReference
If you group them by how low-level they are, the ConcurrentHashMap is the odd one out. Both atomics and monitors are native concepts in the Java world. You can’t implement them, whilst the hash map is a useful class from standard library that is itself implemented with the use of monitors. You might find interesting to know the ConcurrentHashMap uses a technique called lock stripping, where it uses multiple monitors, each of which protects a non-overlapping section of the map. This way, multiple threads can change the map at the same time, provided they do it in different sections.
We will go with AtomicReference.
Atomics were introduced in Java 5. They are more low-level than intrinsic locks (and therefore than ConcurrentHashMap ‘s) as they are at least partially supported by the hardware layer itself, rather than the operating system, which is solely responsible for supporting mutexes and locks.
There are endless resources online explaining how these work. We will avoid any superficial analysis, but rather refresh how they work, and then focus on 1 important point most other resources often don’t mention.
An atomic reference contains, well, a reference. Its distinctive power is that of allowing you to swap that reference for a new reference atomically and with the new reference depending on the old reference. The operation never blocks any threads, and if it fails you can retry. The pattern we will use for methods connect, announce, and re-announce will be the following:
// Only Scala code for brevity. Java source code would be almost indistinguishable.
class TrackerImpl(
state: AtomicReference[Map[InfoHash, Map[InetSocketAddress, TrackerState]]]
) {
def someMethod() = {
val currentState: Map[InfoHash, Map[InetSocketAddress, TrackerState]] = state.get()
val newState: Map[InfoHash, Map[InetSocketAddress, TrackerState]] = ???
if (!state.compareAndSet(currentState, newState)) someMethod()
else {/* reference "swap" succeeded, so lets continue */}
}
}Atomic references + Immutable objects
What other articles fail to mention is that slapping an atomic reference on some data structure doesn’t automatically make it thread-safe without further considerations. Atomic references provide only semantics for the reference it contains, not what the reference points to. If the reference points to mutable data, mutating it will not be thread-safe.
Consider the following.
// Example just in Java source code.
import java.util.concurrent.atomic.AtomicReference;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Test {
AtomicReference<Map<String, List<String>>> sharedState = new AtomicReference<>(new HashMap<>());
void badDev() {
Map<String, List<String>> theMap = sharedState.get();
List<String> theList = theMap.get("foo");
if (theList != null) {
theList.add("bar");
} else {
List<String> newList = new ArrayList<>();
newList.add("bar");
theMap.put("key", newList);
}
}
public void distractedDev() {
Map<String, List<String>> currentMap = sharedState.get();
Map<String, List<String>> theNewMap = new HashMap<>();
for (Map.Entry<String, List<String>> entry : currentMap.entrySet()) {
String theKey = entry.getKey();
List<String> theValue = entry.getValue();
theValue.add("monkey");
theNewMap.put(theKey, theValue);
}
if (!sharedState.compareAndSet(currentMap, theNewMap)) distractedDev();
}
public void goodDev() {
Map<String, List<String>> currentMap = sharedState.get();
Map<String, List<String>> theNewMap = new HashMap<>();
for (Map.Entry<String, List<String>> entry : currentMap.entrySet()) {
String theKey = entry.getKey();
List<String> newList = new ArrayList<>(entry.getValue());
newList.add("monkey");
theNewMap.put(theKey, newList);
}
if (!sharedState.compareAndSet(currentMap, theNewMap)) goodDev();
}
}badDev shows the incorrect usage of atomic references. sharedState.get() doesn’t create any a lock of any kind, it just gives you the underlying reference. If multiple threads run this method concurrently, they will be mutating the map and list at the same time.
This is a daft example. Only someone unaware of how this work would do that.
distractedDev shows a more realistic scenario. He knows he has to create a new map instance and copy the original into it.
However, either due to distraction of being unsure of the semantics, when creating the value for each key, instead of creating a new list, he mutates the original, and then uses its reference. But this reference is the same other threads see and are add`ing to. So the `theNewMap we are assigning to the atomic reference contains changes introduced by another thread.
Similarly, you have to be careful about “publishing” those mutable data structures. By publishing we mean sharing references with code that you do not control, as it happens when you are developing an API of a library to be imported by others. From the example above, if you have a getter method that returns the underlying map (e.g. sharedState.get()), then any client would get the reference to the underlying mutable state and be able to change it from the outside likely breaking the invariants.
The best remedy to this is to use immutable data-structures. For Scala, the default is always immutable collections. You don’t even need to import them. Immutability in Java is less prevalent. We will be relying on Google’s Guava library (com.google.guava:guava:31.1-jre) and its ImmutableMap, ImmutableList, and ImmutableSet. As a reference, the Vavr.io library would probably be more appropriate.
Notice however that using immutable structures might come at a price. We need to create a new data-structure every time. In the goodDev() example, whilst it is correct from the point of view of thread safety and concurrent access, we need to clone the entire list onto a new list. This might be prohibitive for large collections. Collection libraries that have immutability as their core principle, can and do design it in such a way to make immutable operations very performant.
Connect
Before requesting the peers from the tracker, the protocol specifies we have to establish a “connection” with the tracker.
public class TrackerImpl implements Tracker {
DatagramSocket socket;
AtomicReference<ImmutableMap<InfoHash, State>> sharedState;
Executor ex;
// remaining code
CompletableFuture<Pair<ConnectResponse, Long>> connect(
InfoHash torrent, InetSocketAddress tracker, int n) {}
}Calling this method implies that we try to establish a connection with the tracker, and the returned future can complete only once the operation succeeds. According to the protocol, that implies we send a connection request over UDP, and the tracker sends a matching connection response. Matching means the response contains the same transaction id that we sent on the request.
Importantly, notice that this future must ultimately be completed by the reader thread, as that is where any connection response is received.
We can start with the following code:
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetSocketAddress;
import java.net.SocketException;
import java.util.concurrent.atomic.AtomicReference;
import org.javatuples.Pair;
public class TrackerJavaImpl implements TrackerJava {
DatagramSocket socket;
AtomicReference<ImmutableMap<InfoHash, State>> sharedState;
TransactionIdGenerator txdIdGen;
Executor ex;
Config config;
// remaining code
CompletableFuture<Pair<ConnectResponse, Long>> connect(
InfoHash torrent, InetSocketAddress tracker, int n) {
ImmutableMap<InfoHash, State> currentState = sharedState.get();
State state4Torrent = currentState.getOrDefault(torrent, null);
if (state4Torrent == null) {
return CompletableFuture.failedFuture(
new IllegalStateException(
String.format("Connecting to %s but '%s' doesn't exist.", tracker, torrent)));
} else {
int txnId = txdIdGen.txnId();
CompletableFuture<Pair<ConnectResponse, Long>> promise =
new CompletableFuture<Pair<ConnectResponse, Long>>();
State newState4Torrent =
new State(
state4Torrent.peers(),
ImmutableMap.<InetSocketAddress, TrackerState>builder()
.putAll(
state4Torrent.trackers().entrySet().stream()
.filter(a -> !a.getKey().equals(tracker))
.collect(ImmutableList.toImmutableList()))
.put(tracker, new TrackerState.ConnectSent(txnId, promise))
.build());
ImmutableMap<InfoHash, State> newState =
ImmutableMap.<InfoHash, State>builder()
.putAll(
currentState.entrySet().stream()
.filter(a -> !Objects.equals(a.getKey(), torrent))
.collect(ImmutableList.toImmutableList()))
.put(torrent, newState4Torrent)
.build();
if (!sharedState.compareAndSet(currentState, newState)) return connect(torrent, tracker, n);
else {
sendConnectDownTheWire(txnId, tracker);
return promise;
}
}
}
private void sendConnectDownTheWire(int txnId, InetSocketAddress tracker) {
byte[] payload = new ConnectRequest(txnId).serialize();
try {
socket.send(new DatagramPacket(payload, payload.length, tracker));
} catch (Exception error) {
// maybe log
}
}
}As you might have expected, inside this method we must trigger a network call, whereby we send a connection request packet. Before sending it though, we ought to change the shared state of the tracker to ConnectSent with the chosen transaction id. If we were to send the message before changing the state, we would expose the system to a race condition, whereby the tracker sends the connection response and this is processed by the reader thread before the shared state changes. In that case the reader thread would need to ignore that message, as the tracker is not yet registered. That means there will be a brief period of time when the state for a tracker is ConnectSent, but no connect request message has actually been sent. This is not an issue.
Notice that we do not want to do udpSocket.read after sending. We already discussed that there is only one socket for reading. If we were to read here, we might read a packet corresponding to another tracker.
Similarly, we don’t block the future, as then we would be blocking the current thread with its associated dangers. We could be starving the thread pool backing the future.
The second point is that the state ConnectSent from earlier now contains the future to be completed alongside the transaction id:
record ConnectSent(int txdId, CompletableFuture<Pair<ConnectResponse, Long>> fut) implements TrackerState {}
This is a key point. Because the connection response will be received and processed by the reader thread, it needs a reference to that future so that it can complete it. The future is created and “edited” by some thread in the execution context thread pool, and is completed by our reader thread. That is completely fine. Futures are thread-safe. In fact, this is the all point of the future: to share values safely across thread boundaries. One thread completes the future and one or more other thread “get notified” once the completion occurs.
We can see how that future is completed by the reader thread:
final class TrackerReader implements Runnable {
final DatagramSocket udpSocket;
final AtomicReference<ImmutableMap<InfoHash, State>> theSharedState;
final int packetSize = 65507;
@Override
public void run() {
while (true) {
DatagramPacket dg = new DatagramPacket(new byte[packetSize], packetSize);
try {
udpSocket.receive(dg);
} catch (IOException e) {
throw new RuntimeException(e);
}
process(dg);
}
}
private void process(DatagramPacket dg) {
int payloadSize = dg.getLength();
InetSocketAddress origin = (InetSocketAddress) dg.getSocketAddress();
if (payloadSize == 16) {
try {
ConnectResponse connectResponse = ConnectResponse.deserialize(dg.getData());
processConnect(origin, connectResponse, System.nanoTime());
} catch (Error e) {
logger.error(
String.format("Deserializing to connect response from '%s'", dg.getSocketAddress()), e);
}
} else {
// Not implemented
}
}
private void processConnect(
InetSocketAddress origin, ConnectResponse connectResponse, long timestamp) {
ImmutableMap<InfoHash, State> currentState = theSharedState.get();
ImmutableList<TrackerState.ConnectSent> thistha =
currentState.entrySet().stream()
.flatMap(
entry -> {
State state4Torrent = entry.getValue();
return state4Torrent.trackers().entrySet().stream()
.flatMap(
t ->
switch (t.getValue()) {
case TrackerState.ConnectSent lk -> {
if (lk.txdId() == connectResponse.transactionId()
&& t.getKey().equals(origin)) yield Stream.of(lk);
else yield Stream.empty();
}
default -> Stream.empty();
});
})
.collect(ImmutableList.toImmutableList());
int size = thistha.size();
if (size == 1) {
TrackerState.ConnectSent conSent = thistha.get(0);
conSent.fut().complete(new Pair<>(connectResponse, timestamp));
} else if (size == 0) {
logger.info(
String.format(
"No trackers waiting connection for txdId %s. All trackers: ???.",
connectResponse.transactionId()));
} else {
logger.info("Fooar ---");
}
}
}Scala’s vs Java’s future
Retries
We are nearly there. As it stands, the connect method will return a future that will complete successfully when and if we receive a matching response from the tracker. But, due to the nature of UDP, messages might get lost. We might not receive the matching connection response from the tracker for a variety of reasons. The future would then never complete, preventing the system from progressing. We would never get any peers from that tracker.
For that reason, as we have discussed, the UDP Tracker protocol, specifies retries. We must encode the behaviour of waiting for a time interval for the response before sending a new request. The time interval increases in an exponential backoff fashion.
We can do this by timing out the future. In Java, the CompletableFuture provides an easy way to do that. In Scala, we have to do it manually.
import java.util.concurrent.{ScheduledExecutorService, TimeUnit}
import java.util.concurrent.duration.FiniteDuration
import scala.concurrent.{ExecutionContext, Future, Promise, TimeoutException}
final class TrackerImpl private (
scheduler: ScheduledExecutorService
// other dependencies
) extends Tracker {
// remaining code
private def timeout[A](fut: Future[A], timeout: FiniteDuration)(implicit ec: ExecutionContext): Future[A] = {
val promise = Promise[A]()
scheduler.schedule(
new Runnable { override def run(): Unit = promise.tryFailure(new TimeoutException(s"Timeout after $timeout.")) },
timeout.toMillis,
TimeUnit.MILLISECONDS
)
fut.onComplete(promise.tryComplete)
promise.future
}
}So by passing an original future value (fut above) this method returns a brand-new future. And this new future will be completed when the original completes, or it will be completed with a TimeoutException after the specified timeout, whichever occurs first. Again we use Scala’s future/promise “bridge pattern”.
Java provides that functionality directly via the public method orTimeOut on its futures. Its implementation is similar to what we do here for Scala. Whilst here we have a ScheduledExecutorService dependency that we can control, Java creates a single ScheduledExecutorService with a single thread that is responsible to timeout all the futures. You can see this by perusing the Java docs of CompletableFuture starting at orTimeOut.
Armed with this we now obtain the final implementation.
import java.net.{DatagramPacket, DatagramSocket, InetSocketAddress}
final class TrackerImpl private (
state: AtomicReference[Map[InfoHash, Map[InetSocketAddress, TrackerState]]],
executionContext: ExecutionContext,
udpSocket: DatagramSocket
// other dependencies
) extends Tracker {
// remaining code
private def connect(infoHash: InfoHash, tracker: InetSocketAddress)(implicit
ec: ExecutionContext
): Future[(ConnectResponse, Long)] = {
def inner(n: Int): Future[(ConnectResponse, Long)] = {
val currentState = state.get()
currentState.get(infoHash) match {
case Some(State(peers, trackers)) =>
val txdId = txnIdGen.txnId()
val promise = Promise[(ConnectResponse, Long)]()
val newState4Torrent = State(peers, trackers = trackers + (socket -> ConnectSent(txdId, promise)))
val newState = currentState + (infoHash -> newState4Torrent)
if (!state.compareAndSet(currentState, newState)) inner(n)
else {
sendConnectDownTheWire(txdId, tracker)
timeout(promise.future, TrackerImpl.retries(math.min(8, n)).seconds).recoverWith {
case _: TimeoutException => inner(n + 1)
}
}
case None => Future.failed(new IllegalStateException(s"Connecting to $tracker but '$infoHash' doesn't exist."))
}
}
inner(0)
}
}promise.future is a (future) value that is completed once the remote tracker sends back the appropriate connect response (i.e. connect response with matching transaction id) and the reader thread receives and completes the associated promise.
timeout(promise.future, TrackerImpl.retries(math.min(8, n)).seconds) returns a different future that completes successfully or unsuccessfully when promise.future completes, or completes unsuccessfully with a timeout exception when a time interval has passed counting from the moment that line of code ran. Whichever occurs first.
Lastly, timeout(promise.future, TrackerImpl.retries(math.min(8, n)).seconds).recoverWith { case _: TimeoutException ⇒ returns yet another future that completes successfully when
sendConnect(infoHash, tracker, n + 1)
}promise.future completes or keeps trying forever. In each retry, it sends another connect request to the tracker with a different transaction id.
What happens when the reader thread receives a matching connection response immediately after the corresponding future times out? This can and will definitely happen. The important job about concurrency is to think about all the corner cases of how threads and events can interleave.
It depends on what is the shared state. If the state for the tracker is still ConnectSent with the original transaction id, the Reader thread would be able to match and complete the associated future. However, futures can only be completed once. Trying to complete it again, would have no effect.
Alternatively, if by that time the response is received, a new connection request has been sent, the transaction id in the state of ConnectSent would have been different from the id received by the reader thread, which in return would discard the message altogether.

Address usage of AtomicReference.
Announce
After we receive a matching connect response, we need to send an announce request. The response to which will finally contain a list of the peers for that torrent (revisit the diagram).
The implementation of announce(): Future[AnnounceResponse] is very similar to the one we have just seen for connect.
import java.net.{DatagramPacket, DatagramSocket, InetSocketAddress}
private[tracker] final class TrackerImpl private (
state: AtomicReference[Map[InfoHash, Map[InetSocketAddress, TrackerState]]],
executionContext: ExecutionContext,
udpSocket: DatagramSocket
// other dependencies
) extends Tracker {
// remaining code
private def announce(
infoHash: InfoHash,
tracker: InetSocketAddress,
connection: Connection
)(implicit ec: ExecutionContext): Future[AnnounceResponse] = {
def inner(n: Int): Future[AnnounceResponse] = {
val currentState = state.get()
currentState.get(infoHash) match {
case Some(state4Torrent @ State(_, _)) =>
val txdId = txnIdGen.txnId()
val promise = Promise[AnnounceResponse]()
val announce = AnnounceSent(txdId, connection.id, promise)
val newState = currentState + (infoHash -> state4Torrent.updateEntry(tracker, announce))
if (!state.compareAndSet(currentState, newState)) inner(n)
else {
sendAnnounceDownTheWire(infoHash, connection.id, txdId, tracker)
timeout(promise.future, TrackerImpl.retries(math.min(8, n)).seconds).recoverWith {
case _: TimeoutException =>
if (limitConnectionId(connection.timestamp))
Future.failed(
new TimeoutException(
s"Connection to $tracker (${connAgeSec(connection.timestamp)} s) expired before announce received."
)
)
else inner(n + 1)
}
}
case _ => Future.failed(new IllegalStateException(s"Announcing to $tracker for $infoHash but no such torrent."))
}
}
inner(0)
}
}In particular, we set the state before sending the message down the socket.
In addition to the transaction id and the future (to be completed by the reader thread), AnnounceSent contains also the id of the connection that the tracker needs.
The main difference to the connect is that we don’t retry indefinitely. As the protocol specifies “connections” expire after 60 seconds, we need to request a new connection id. If we don’t receive a matching announce request by then, the future completes with a timeout error. This timeout error will be caught by run.
Now we have announce defined. If it returns successfully, the Future[AnnounceResponse] contains the peers of the torrent network which is what we are looking for.
import java.net.InetSocketAddress
import scala.util.{Failure, Success}
import scala.concurrent.ExecutionContext
private[tracker] final class TrackerImpl private (
state: AtomicReference[Map[InfoHash, Map[InetSocketAddress, TrackerState]]],
executionContext: ExecutionContext
// other dependencies
) extends Tracker {
// remaining code
private def run(torrent: InfoHash, tracker: InetSocketAddress)(implicit ec: ExecutionContext): Future[Unit] =
(for {
(connectRes, timestampConn) <- connect(infoHash, tracker)
connection = Connection(connectRes.connectionId, timestampConn)
announceRes <- announce(infoHash, tracker, connection)
} yield ()) recoverWith { case timeout: TimeoutException =>
logger.warn(s"Obtaining peers from '$tracker' from '$infoHash'. Retrying ...", timeout)
run(infoHash, tracker)
}
}Re-Announcing
We are missing two things. On the one hand we haven’t updated the shared state to add the peers. Therefore, calls to method peers will return an empty set.
Additionally, method run completes once we obtain the list of peers. However, the protocol specifies that we need to keep asking the tracker for new peers. The list of peers is dynamic. It changes as new BitTorrent clients (i.e. peers) join and old clients leave the network.
Addressing the second point is harder. After announce returns, we must wait for a given time and then call announce again. We must now how to delay a future by a certain amount. Scala futures don’t have this functionality built in, but Java’s CompletableFuture has. For Scala, we can do that our selves:
import java.net.InetSocketAddress
import scala.util.{Failure, Success}
import scala.concurrent.ExecutionContext
private[tracker] final class TrackerImpl private (
state: AtomicReference[Map[InfoHash, Map[InetSocketAddress, TrackerState]]],
executionContext: ExecutionContext
// other dependencies
) extends Tracker {
// remaining code
private def after[A](futValue: Try[A], delay: FiniteDuration): Future[A] = {
val promise = Promise[A]()
scheduler.schedule(
new Runnable { override def run(): Unit = promise.tryComplete(futValue) },
delay.toMillis,
TimeUnit.MILLISECONDS
)
promise.future
}
}Method after will return a future that will complete according with futValue after a certain time interval.
With this, we can now have:
import java.net.InetSocketAddress
import scala.util.{Failure, Success}
import scala.concurrent.ExecutionContext
private[tracker] final class TrackerImpl private (
state: AtomicReference[Map[InfoHash, Map[InetSocketAddress, TrackerState]]],
executionContext: ExecutionContext
// other dependencies
) extends Tracker {
// remaining code
private def setAndReannounce(
infoHash: InfoHash,
tracker: InetSocketAddress,
peers: Set[InetSocketAddress],
connection: Connection
)(implicit ec: ExecutionContext): Future[Unit] = {
val currentState = state.get()
currentState.get(infoHash) match {
case Some(state4Torrent @ State(_, _)) =>
val newEntry4Tracker = state4Torrent.updateEntry(tracker, AnnounceReceived(connection.timestamp, peers.size))
val newState =
currentState + (infoHash -> newEntry4Tracker.copy(peers = newEntry4Tracker.peers ++ peers))
if (!state.compareAndSet(currentState, newState)) setAndReannounce(infoHash, tracker, peers, connection)
else
for {
_ <- after(Success(()), config.announceTimeInterval)
_ <-
if (limitConnectionId(connection.timestamp))
failed(new TimeoutException(s"Connection to $tracker (${connAgeSec(connection.timestamp)} s) expired."))
else Future.unit
_ = logger.info(s"Re-announcing to $tracker for $infoHash. Previous peers obtained: ${peers.size}")
announceRes <- announce(infoHash, tracker, connection)
_ <- setAndReannounce(infoHash, tracker, announceRes.peers.toSet, connection)
} yield ()
case _ =>
Future.failed(new IllegalStateException(s"Re-announcing to $tracker for $infoHash but no such torrent."))
}
}
}This method:
- Sets the new peers into the shared state so that they are available to other threads via
peers. - Then waits for a given time interval to announce again.
- When is time to proceed, it checks if the connection has expired.
- If not, announces again.
- This means
- Repeats idenfinitly.