In this article, learn about low-level Java/Scala async file IO:
- How
AsynchronousFileChannelworks. - Where does the IO operation take place?
- The implications of OS write buffers.
TLDR
- On Linux, the
AsynchronousFileChannelmerely shifts a blocking IO operation to an executor service. There is no native support. - It is easier to exhaust available heap memory than with a synchronous
FileChannelif you submit writes faster than the IO operations can complete. - The Operating System (OS) lies. Be mindful that, at a lower level, the OS also presents a concept of asynchronism. Generally, by the time OSes return a IO call, they have only transparently written data to memory buffers. Only after do they actually persist to physical disks.
Introduction
From the point of view of the programmer, asynchronous file IO allows reading/writing data from/into the file system without blocking the calling thread of execution. That is, the thread that requests the operation.
This has always been possible to accomplish by the programmer. Just spawn a new thread responsible for doing the IO operation and allow for some mechanism to communicate the result to other threads – like a future.
But the JDK gives an API out of the box for it via the java.nio.channels.AsynchronousFileChannel. The argument for using it is that some operating systems might provide native support for async IO, where the kernel itself understands and facilitates async file operations.
Note
Asynchronous file channels have not always been around. They were introduced on Java 1.7, within what is known as the “NIO.2” API, standing for New IO (version 2). It complemented the “NIO” API – that had been released on Java 1.4 – by adding asynchronous IO (for sockets as well). Prior, only synchronous file channels were available.
| Classic IO | NIO | NIO.2 | |
|---|---|---|---|
| JDK version | 1.0 | 1.4 | 1.7 |
| Date | inception | 2006 | 2011 |
| Features | FileInputStream, File, … | FileChannel, … | AsynchronousFileChannel |
Why would you want this
It makes your application more responsive. If the application is user facing, the code can return to the user before the reading/writing is completed, which allows him to do something else.
But why do we need a special feature? Why not just do the blocking read/write in a different thread, and use a future as the mechanism to “signal” back when the operation is done?
The reason is the AsynchronousFileChannel provides a facade behind which some platforms use native OS capabilities that do not require threads and are therefore more scalable – as threads have a cost.
API
Lets first have a look on how to use it. We focus on the concurrent aspect of file IO and for this we are only interested in 1) opening a file, 2) reading or writing to it, and 3) closing it. The AsynchronousFileChannel has other capabilities, like locking a file, that we will ignore.
package java.nio.channels;
import java.nio.file.Path;
import java.util.concurrent.Future;
import java.nio.channels.CompletionHandler;
import java.nio.file.OpenOption;
public abstract class AsynchronousFileChannel {
public static open(
Path path,
Set<? extends OpenOption> options, // ExtendedOpenOption.DIRECT and StandardOpenOption.SYNC are of particular importance.
ExecutorService executor);
// ------
public Future<Integer> read(ByteBuffer bytebuffer, long position);
public abstract <A> void read(
ByteBuffer bytebuffer,
long position,
CompletionHandler<Integer,? super A> handler); // Future based API.
// ------
public Future<Integer> write(ByteBuffer bytebuffer, long position);
public abstract <A> void write(
ByteBuffer bytebuffer,
long position,
A attachment, // not relevant for us. Additionally it can be null (or Unit in Scala). We will dismiss it.
CompletionHandler<Integer, ? super A> handler); // Callback based API. Check what the CompletionHandler is from the examples further down.
}The way to create an instance is via the static method open. The actual implementation returned is platform dependent. As with classic FileInputStream s, you should call close after using the file.
Opening
Non surprisingly, path is the location of the file to open, and with options you specify the behavior you expect from the file as well as the purpose of opening it. Possible values include StandardOpenOption.(Read|Write|Create|Truncate), which are self-explanatory.
Less obvious are the options StandardOpenOption.Sync and ExtendedOpenOption.Direct. Their presence has a huge impact (orders of magnitude) on the tests and discussions further ahead.
More interestingly still is executor. This is the thread-pool where the call-backs (i.e. the completion handler) that you provide are executed for all write and read operations which are later performed with that channel.
Crucially, this is not necessarily where the IO operation takes place. Only the handler is guaranteed to run there. The underlying system might be responsible for the IO operation, and signalling truly asynchronously. Interestingly, it looks like for Linux, this is also where a BLOCKING IO operation takes place. That is, in Linux, the implementation is such that the executor runs not only the handler but also a blocking IO call. More on this later.
Lastly, if you don’t provide it, a default is used which depends on the system.
Reading and Writing
There are two flavours for the asynchrony. Either you receive a Future<Integer>, or you provide a callback which is applied to the result of the IO operation once it is available. Obviously, it is the implementation of AsynchronousFileChannel responsible for calling that handler. Linking back to before, the handler is guaranteed to be applied on the executor associated with the file channel.
It’s more pleasant to work with futures, but sadly, the future version returns a java.util.concurrent.Future. Unlike Scala’s Future or Java’s CompletableFuture, it allows only for polling for completion, and blocking until completion. The pattern would end up being something like:
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousFileChannel;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.concurrent.Future;
class SomeClass {
// .... other code....
AsynchronousFileChannel fileChannel = // Can throw, but will ignore.
AsynchronousFileChannel.open(Paths.get("<some-path>"), StandardOpenOption.READ);
ByteBuffer byteBuffer = ByteBuffer.allocate(100);
Future<Integer> bytesReadF = fileChannel.read(byteBuffer, 0); // Can throw, but will ignore.ignore.
while (!bytesReadF.isDone()) {
// do useful work
}
Integer bytesRead = bytesReadF.get();
f(byteBuffer) // Function f not shown. Do something with the bytes read from the file
}The approach is not easily composable. What if you had many such futures to poll? How would one manage all the “useful work” each has to do and how to integrate it in a bigger application? The best alternative are composable futures.
To transform the java.util.concurrent.Future into a Scala future of Java CompletableFuture, one could use another thread pool where we block waiting for completion. That is, we would create a Scala future/promise (or a Java completable future) on the calling thread, and then create another thread (or use an executor service) responsible for blocking on the IO java.util.concurrent.Future, and finally complete that future (the composable one).
This is not ideal. While it would be asynchronous and composable you would still be blocking a thread on some thread pool. This is prone to thread starvation, and it creates as many threads as IO operations, wasting resources.
Alternatively, one could use a single timer/scheduler to poll for many IO futures. Again we would create a composable future on one end. Then, we would submit a task at a given frequency to the scheduler that is responsible for polling (rather than blocking) and complete the composable future if done. The advantage being we would be sharing the scheduler – normally associated with a single, and at most a few threads – amongst many futures. The disadvantage is that we need to decide the polling frequency.
Instead, the approach we will follow is to use the callback API. The advantage is that it provides a way for us to be “notified” as soon as the IO operation completes, rather than us having to design a mechanism around explicitly checking. But we love futures so we will use the callback approach to complete a Scala Future (or Java CompletableFuture). In Scala parlance, this is called a Future bridge:
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousFileChannel;
import java.nio.channels.CompletionHandler;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.Set;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.Executors;
public class Example {
public static void main(String[] args) throws IOException {
AsynchronousFileChannel fileChannel =
AsynchronousFileChannel.open(
Paths.get("<some-path>"),
Set.of(StandardOpenOption.WRITE),
Executors.newSingleThreadExecutor());
CompletableFuture<Integer> promise = new CompletableFuture<>();
fileChannel.write(
ByteBuffer.wrap(new byte[100]),
0L,
null,
new CompletionHandler<>() {
@Override
public void completed(Integer result, Object attachment) {
promise.complete(result);
}
@Override
public void failed(Throwable exc, Object attachment) {
promise.completeExceptionally(exc);
}
});
// promise.completeAsync() ...
}
}Who completes the IO
Blowing up memory
Conceptually, regardless where the IO is done, async file IO will be vulnerable to “memory crashes”. If you submit IO writes faster than the filesystem or disk is able to process, the data must necessarily be stored somewhere. If they are stored in user-space buffers on the Java side, then OutOfMemory errors occur.
This is fundamentally different from the traditional blocking IO. When the reads/writes occurs synchronously, the calling thread cannot execute a new operation until the previous completed. No objects need to be stored in a temporary queue/buffer. There is an inherent back-pressure control. Obviously, the argument applies for a single thread only. There is no such “back-pressure” control mechanism across several spawned threads.
A good way to observe this vulnerability of async file IO is to 1) plug in a slow USB flash drive, 2) reduce the maximum heap size (-Xmx) of the JVM, and 3) submit a series of asyn writes over that threshold:
import java.nio.ByteBuffer
import java.nio.channels.{AsynchronousFileChannel, CompletionHandler}
import java.nio.file.{OpenOption, Paths}
import java.nio.file.StandardOpenOption.{CREATE, TRUNCATE_EXISTING, WRITE}
// Remember this option `DIRECT`. It will be discussed later and has huge impact on latency, throughput, and actual behavior.
import com.sun.nio.file.ExtendedOpenOption.DIRECT
import cats.implicits.toTraverseOps
import java.util.concurrent.Executors
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.duration.Duration
import scala.concurrent.{Await, Future, Promise}
import scala.jdk.CollectionConverters.SetHasAsJava
import scala.util.{Failure, Success}
object OutOfMemoryErrorExample {
def main(args: Array[String]): Unit = {
val openOptions: Set[OpenOption] = Set(WRITE, TRUNCATE_EXISTING, CREATE, DIRECT)
val usbPath = Paths.get("path-to-slow-usb-drive")
val ec = Executors.newSingleThreadExecutor()
val numFiles = 100
val sizeMbFiles = 15
val fileChannels: List[AsynchronousFileChannel] =
(1 to numFiles)
.map(idx => usbPath.resolve(s"$idx.TXT"))
.map(path =>
AsynchronousFileChannel
.open(path, openOptions.asJava, ec)
)
.toList
val submitted: List[Future[Unit]] =
fileChannels.map { fC =>
val promise = Promise[Unit]()
fC.write(
ByteBuffer.wrap(new Array[Byte](sizeMbFiles * 1024 * 1024)),
0,
(),
new CompletionHandler[Integer, Unit] {
override def completed(result: Integer, attachment: Unit): Unit = promise.success(())
override def failed(exc: Throwable, attachment: Unit): Unit = promise.failure(exc)
}
)
promise.future.andThen {
case Failure(_) => println("An exception occurred.")
case Success(_) => println("Wrote to a file.")
}
}
// submitted.sequence transforms a list of futures into a future of a list. We are using the cats library for expediency, but this can easily be achieved by us (both in Scala and in Java’s CompletableFuture)
Await.result(submitted.sequence, Duration.Inf)
println("Finished")
}
}For the code above, and with -Xmx1g and 15 MB files, 10 files succeed, but for 100 (~ 1.5 GB) a java.lang.OutOfMemoryError is thrown as the USB flash drive is much slower than the creation of the byte buffers and submission of the writes.
This would not have happened with equivalent code using a FileChannel. As the writes are synchronous from the point of view of the Java application, we would not be creating a new byte buffer until the previous has been written to the file system (provided we stuck with one calling thread)
At the same time, we could fix this by using an ExecutorService with a bounded queue. If the write submissions are faster than the writes to the file system, the queue fills up and starts rejecting further writes. We could catch the error thrown, and retry the write some time later.
Who completes the IO
Above, per the docs, only the callback handler is guaranteed to run on the executor the channel was opened with. When the AsynchronousFileChannel calls the handler (again, on the executor), the IO operation has already finished. The interesting question is where/how the IO operation itself is achieved?
For Windows the implementation of AsynchronousFileChannel seems to rely on native features of the underlying system where the kernel does have async support. In this case, there is no thread responsible for the IO operation, at least on the Java side. You pass to the system the ByteBuffer instance to read to (or write from) alongside a thread pool that the native method call then uses to execute the call-backs. But the IO operation itself is not done there.
/**
* Windows implementation of AsynchronousFileChannel using overlapped IO.
*/
public class WindowsAsynchronousFileChannelImpl
extends AsynchronousFileChannelImpl
implements Iocp.OverlappedChannel, Groupable
{
// .... implementation
}In general however, and in particular on Linux, the default implementation is sun.nio.ch.SimpleAsynchronousFileChannelImpl.
/**
* "Portable" implementation of AsynchronousFileChannel for use on operating
* systems that don't support asynchronous file IO.
*/
public class SimpleAsynchronousFileChannelImpl extends AsynchronousFileChannelImpl
{
// implementation
}If we follow the source code of the latter implementation, it becomes clear that it is simply using the executor service of the channel (which you can specify) to submit a runnable which contains a synchronous IO operation followed by:
- If a future-based call, the completion of the future with the result.
- If call-back based, applying the handler to the result.
The system works as represented on the diagram below. For an executor service shared by many file channels, every time one calls write, a new Runnable instance is created and inserted onto the queue of tasks of that executor service. That Runnable does essentially does two things. First it runs the blocking IO call to write to the file returning the number of bytes written, and then it takes that number and applies it to the completion handler passed on, or, for the future based version, it completes the future. This Runnable waits on the queue until eventually being picked up by one of the threads of the executor.
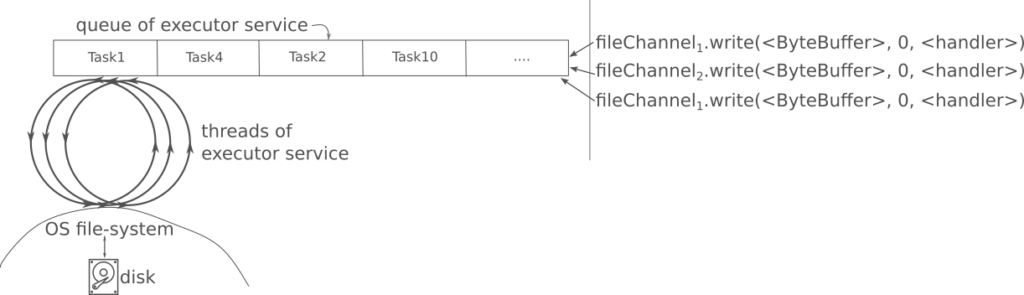
Investigating the executor
To further explore where the IO takes place, and what the executor is used for, we can create a bespoke one that registers basic statistics on the tasks submitted. The following keeps track of the time duration of each task it runs:
import java.util
import java.util.concurrent.atomic.AtomicReference
import java.util.concurrent.{AbstractExecutorService, ExecutorService, TimeUnit}
import scala.util.{Failure, Success, Try}
final class TrackingExecutorService private (delegatee: ExecutorService, submissions: AtomicReference[List[Try[Long]]])
extends AbstractExecutorService {
def getSubmissions: List[Try[Long]] = submissions.get()
private def addSubmission(submission: Try[Long]): Unit = {
val currentState = submissions.get()
if (!submissions.compareAndSet(currentState, currentState :+ submission)) addSubmission(submission)
}
private class TrackingRunnable(delegate: Runnable) extends Runnable {
override def run(): Unit = {
val start = System.nanoTime()
Try(delegatee.run()) match {
case Failure(exception) =>
addSubmission(Failure(exception))
throw exception
case Success(()) =>
val tookMillis = (System.nanoTime() - start) / 1_000_000L
addSubmission(Success(tookMillis))
}
}
}
override def execute(command: Runnable): Unit = delegatee.execute(new TrackingRunnable(command))
override def shutdown(): Unit = delegatee.shutdown()
// All other methods delegate to the underlying executor
}
object TrackingExecutorService {
def apply(delegatee: ExecutorService): TrackingExecutorService =
new TrackingExecutorService(delegatee, new AtomicReference[List[Try[Long]]](List.empty))
}Using this executor, if we open a set of files with AsynchronousFileChannel, and then write some random data into them, how do we expect the duration of each task to vary with the size of the writes? You might expect the time duration to be independent of the size of the files, as you might think the executor is used only to call the completion handler. Alas, there results are:
| Write size per File | # Files | average (ms) | 50p (ms) | 90p (ms) |
|---|---|---|---|---|
| 10 MB | 100 | 6 | 6 | 9 |
| 100 MB (x10) | 50 | 62 | 56 (x9.3) | 86 |
| 200 MB (x2) | 25 | 141 | 113 (x2) | 223 |
| 400 MB (x2) | 10 | 222 | 225 (x2) | 425 |
AsynchronousFileChannel with size of write chunk written to. Running on LinuxNote
The tests above were without ExtendedOpenOption.DIRECT. With this flag, all the durations would be orders of magnitude higher (i.e. each write is slower), but the linear dependency would still be verified, which is what we are trying to show. As discussed later, without the flag the writes are much faster because the OS is writing to buffers in memory, not to actual physical disk.
The durations grow roughly linearly with the size of the files. This corroborates, perhaps surprisingly to most, that the asynchronous file channel merely shifts the IO operation onto another thread of execution. It doesn’t have any “native” support.
OS write buffers
We have established the executor service is where synchronous IO takes place. Lets see what is the effect of its number of threads.
You would expect that for a single physical disk, having more threads would provide no benefit since physical disks handle requests one by one.
Alas, when we try with 2 threads, writing to files is noticeably faster.
| 200 files @ 1 MB | 12 files @ 16 MB | |||
| total time | average time | total time | average time | |
| 1 thread, 1 disk | 207 ms | <1ms | 182 ms | 13 ms |
| 2 threads, 1 disk | 146ms | <1ms | 126 ms | 16 ms |
What is going on? Using a slow, plugable USB flash drive as the destination of our file writes provides an hint. If the USB has a LED light, as some do, you will notice intermittent flashing of the LED long, long after your file writes have completed from the point of view of the JVM application. Potentially only minutes or hours after will the LED turn-off of be at constant light. Intermittent flashing indicates OS is accessing the USB! Furthermore, if your program tries to exit or close the files that you have written to, that is, close the AsynchronousFileChannel, the operation will take a very long time to complete. For example, for the table above, closing all the files for the 2 threads case took around 8 minutes!
What is happening is that when the JVM requests the IO write operation to the OS, for performance reasons the OS writes the data into memory first as it is orders of magnitude faster than physical disks. This is done transparently to your application, and from its point of view the data is written. But its a only a facade managed by the OS. Only later, when the OS so chooses, is the data written to actual physical device. This is performant, but does make reasoning more complex. In our case, that explains why having two threads speeds the writing. There is no bottleneck of a serial physical device, as the 2 threads are actually writing to a memory buffer.
This also means that if you were to physical remove the USB drive prematurely, the data allegedly written to the file system would be lost. Notice however that this OS write buffer is independent of our usage of AsynchronousFileChannel. Had we used a normal file channel or the standard FileInputStream, it would still occur.
One way to try bypass memory buffers is to open the file with flag ExtendedOpenOption.Direct. This instructs the underlying OS that data memory buffers should be avoided. A flag with similar effects is StandardOpenOption.SYNC. The results are then as expected. Having more threads than disks not only doesn’t help but is very detrimental for performance, but having more threads and more disks does help.
Importantly, closing the opened files after writing is a relatively fast operation. As the OS is now writing to physical disk before reporting the IO operation as completed to the calling JVM application, when it comes to closing the file, there is nothing remaining to be written.
| 200 files @ 1 MB | 12 files @ 16 MB | |||
| total time | average time | total time | average time | |
| 1 thread, 1 disk | 16 s | 78 ms | 15 s | 1.26 s |
| 2 threads, 1 disk | 550 s | 5.5 s*1 | 162 s | 27 s*1 |
| 1 thread, 2 disks | 16 s | 78 ms | 19 s | 1.6 s |
| 2 threads, 2 disks | 8 s | 79 ms | 7.7 s | 1.3 s |
ExtendedOpenOption.Direct. Average of 5 cold-start runs.*1: Huge variance on each run across all the files (200, and 12)
Note
When not specified, the following system applies:
- JDK: openjdk-17.0-amd64
- OS: Ubuntu 20.04.6
- Scala: 2.13.10
- Physical disks: USB 2.0 16GB, FAT32
Conclusion
- On Linux, Java’s
AsynchronousFileChanneldoes not support truly async file IO. Instead, it sends a synchronous IO operation onto a common thread pool that you pass as a parameter. - There are two sources of asynchronism. One is the
AsynchronousFileChannel– the main target of the article. The other is due to the fact that the OS writes to memory buffers first, and only then (after it has return the call of the application) synchronizes with the physical device. These mechanisms are independent, but you are able to open a file channel that instructs the OS to bypass such buffers.