Most blogs explaining Java’s CompletableFuture rely on trivial examples (looking at you javatpoint). Those examples can already be provided and well-explained by ChatGPT et al. Furthermore, while they provide only a shallow understanding for beginner developers, they fail to offer anything challenging or insightful for seasoned developers.
A more interesting and insightful example of the usage of CompletableFuture is to create a very simple web-crawler:
- Web-crawler, that starts at a page of website A, and follows the links that lead him to website B.
- Simple and short (~ 150 lines)
- Only using CompletableFutures as the mechanism for concurrency.
The example will be centred around crawling websites, where we will use Java’s HttpClient for downloading pages, for no other reason than its API is very simple, and returns a CompletableFuture.
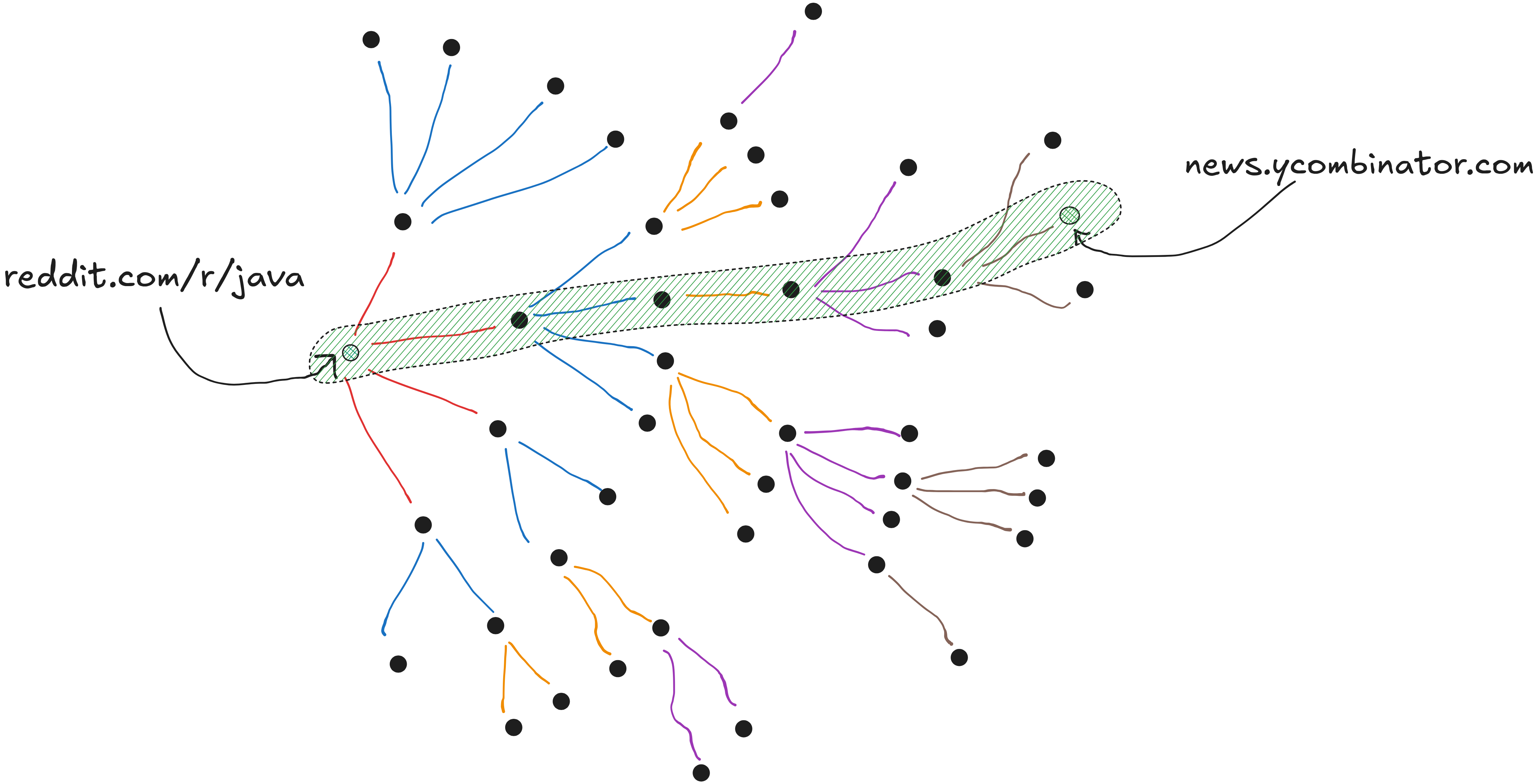
Through the example, we try to reach a hacker-news page from reddit/r/java:
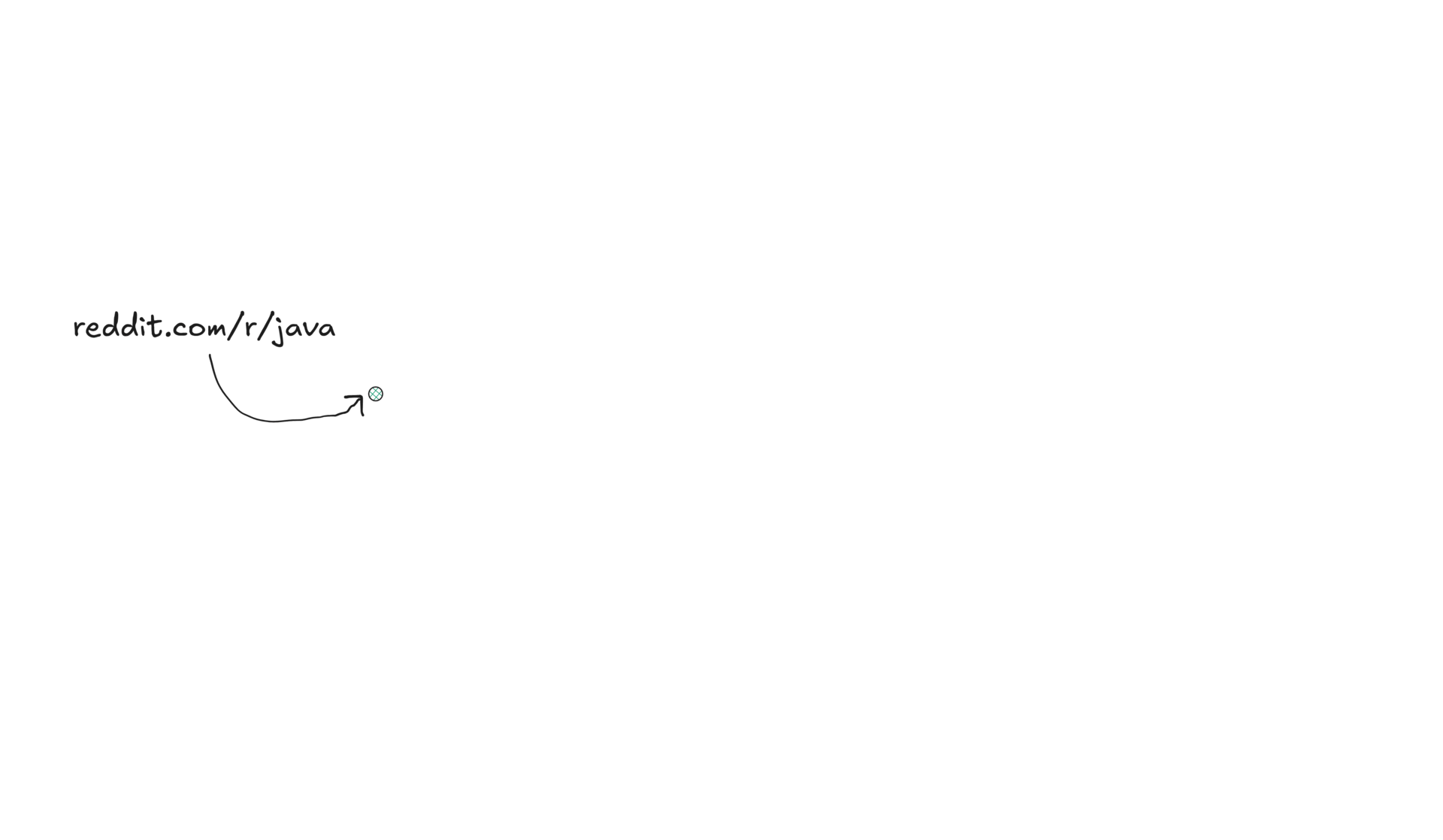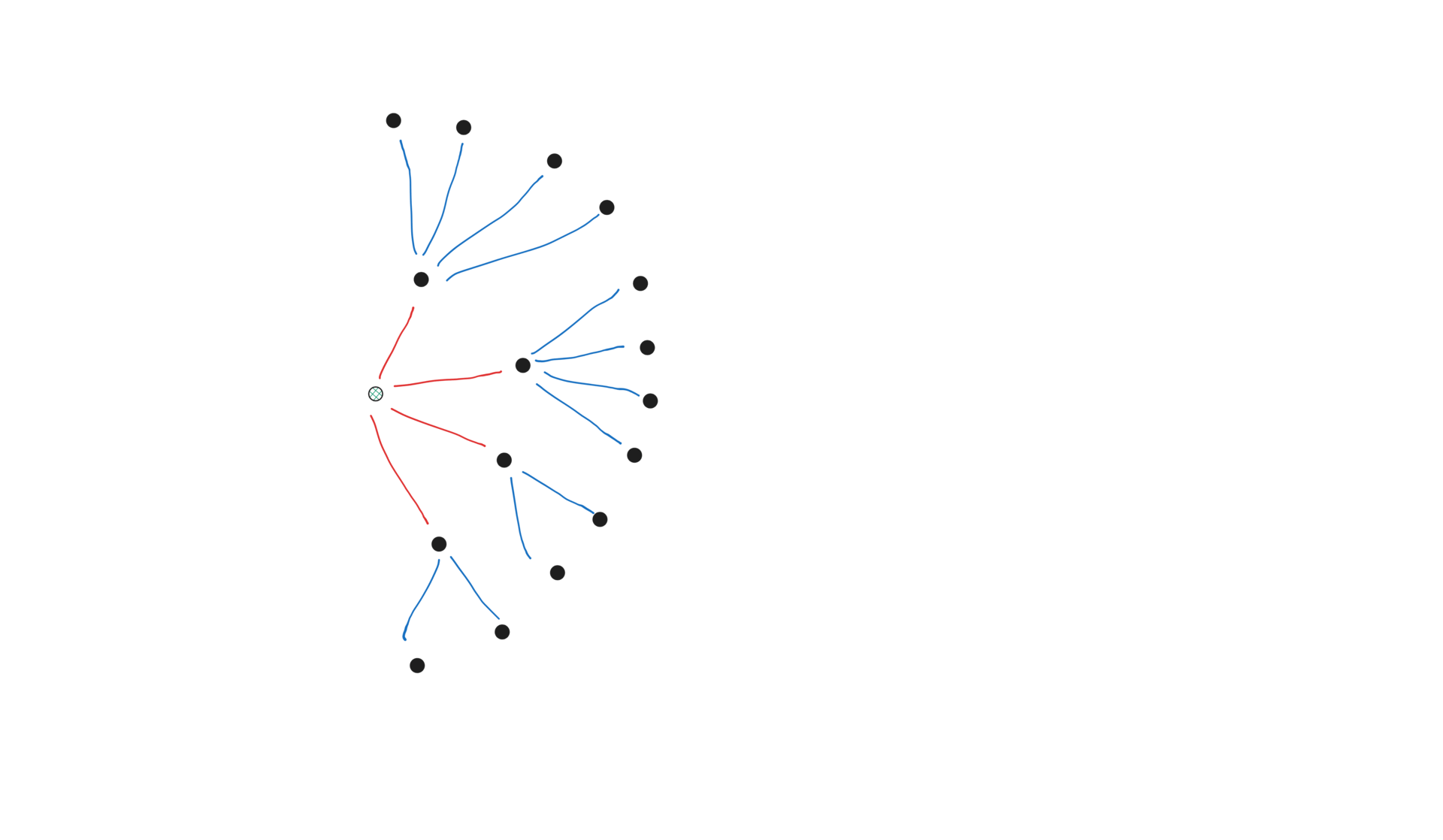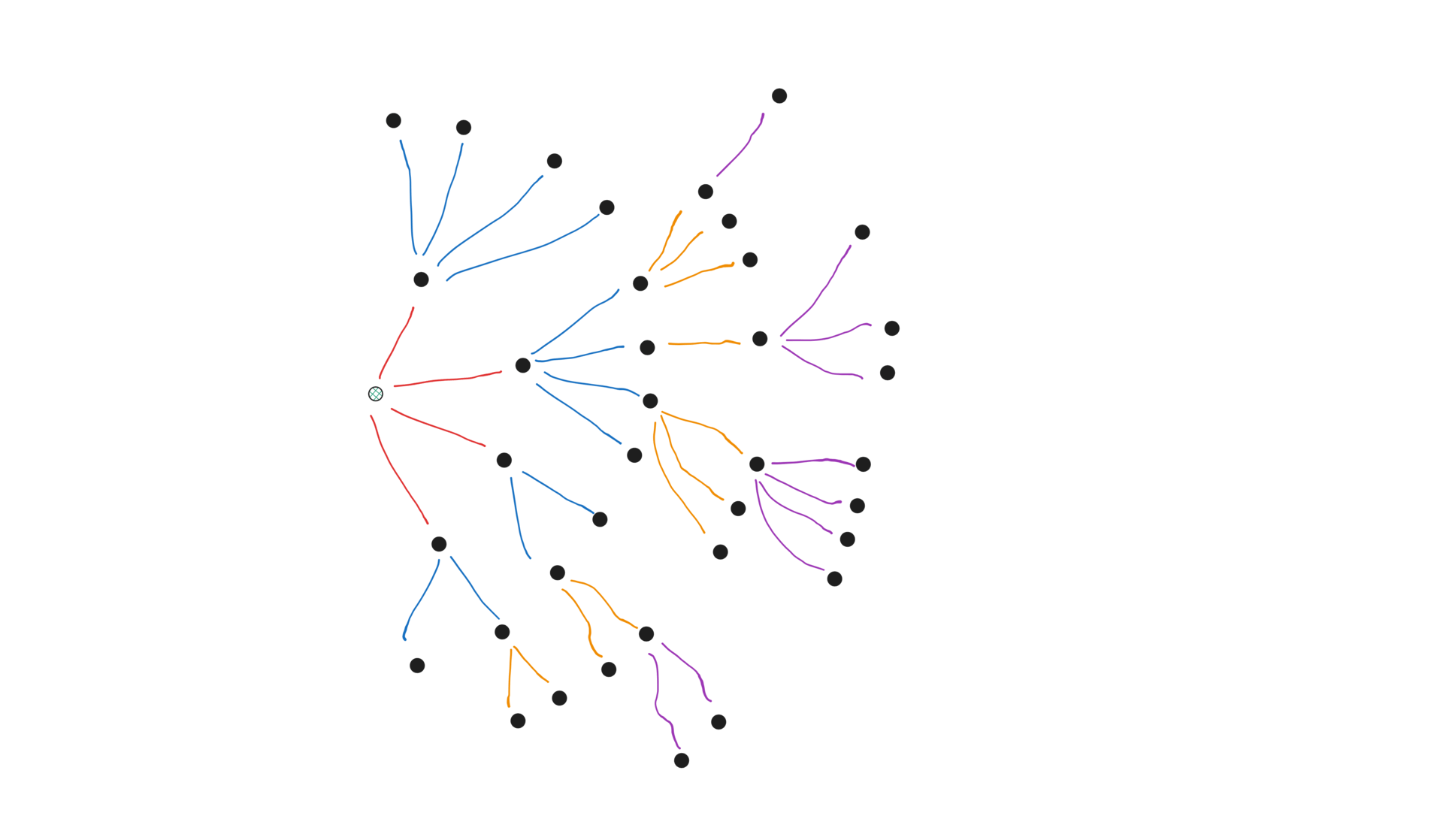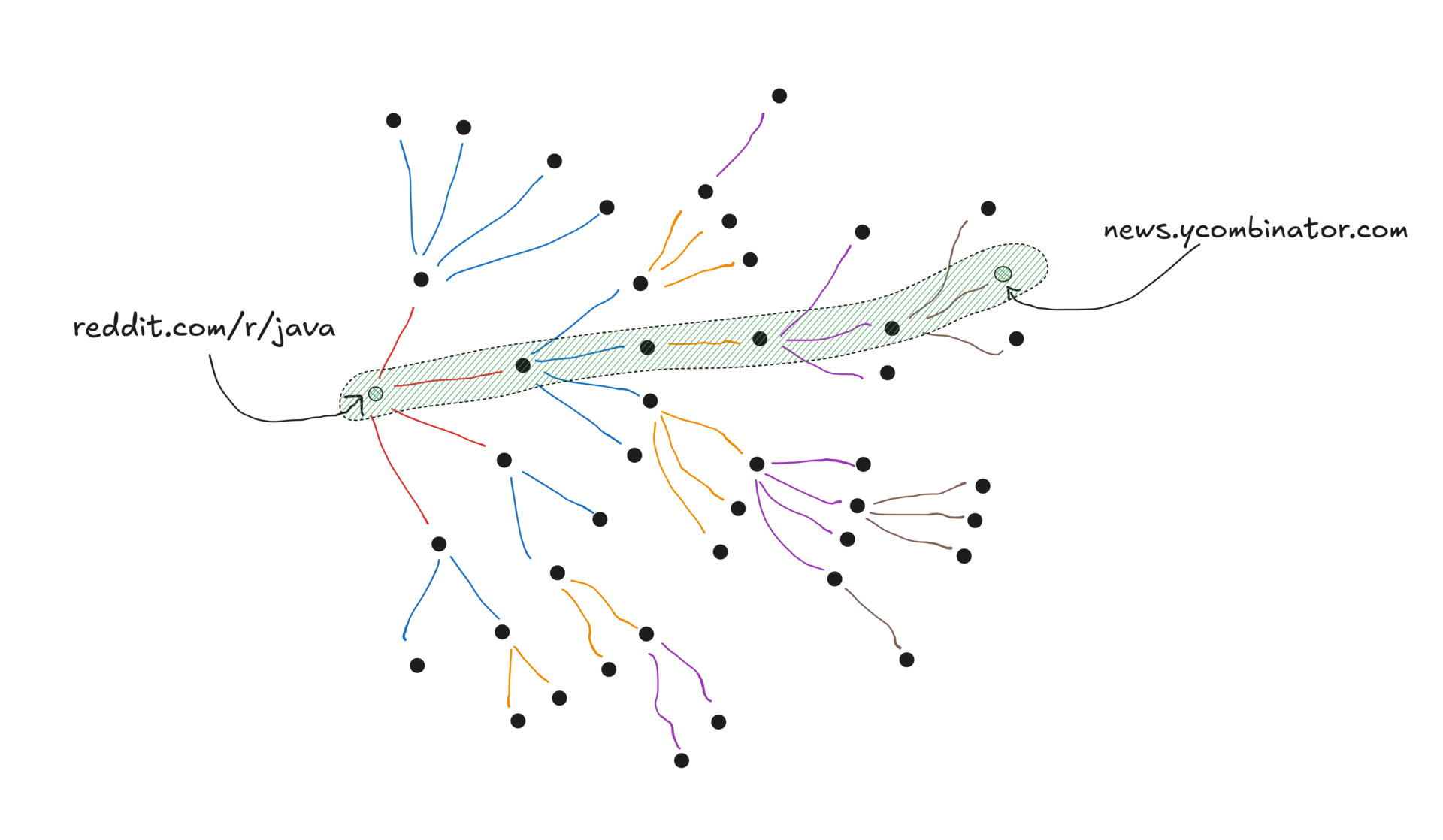
You can find the entire source-code on github.
Running the code above today gave the output:
Done:
https://reddit.com/r/java
https://romankudryashov.com/blog/2024/07/event-driven-architecture/
https://kafka.apache.org/documentation/
https://www.rabbitmq.com
https://news.ycombinator.com/itemRequirements
HttpClient on Java 11
The example will be centred around crawling websites using Java’s HttpClient, for no other reason that the API is very simple and returns a CompletableFuture.
The client comes from the standard library and was introduced in Java 11. Therefore, to reproduce these examples, you need at least Java 11. But you can still follow this post without it.
Jsoup
Allows us to parse the HTML of the web-pages and extract all its external links. Our usage of the library is contained to 3 simple lines. So no point in debating further. Alternatively, we could have used a regex.
Vavr
Vavr is a functional library for Java.
We will use its immutable linked-list to represent the path between the two web-pages.
The reason is that collections in Java’s standard library are mutable, but the crawler is highly concurrent, and immutability makes concurrency much easier to reason about. Additionally, the functional API makes the code more succinct.
That said, you could easily change this to use normal lists and sets. Actually, I half-regret using vavr, as that might put-off some devs.
HttpClient API
The standard libraries’ HttpClient is quite simple. It allows you to send requests and retrieve responses without fluff.
class HttpClient {
// async.
<T> CompletableFuture<HttpResponse<T>> sendAsync(HttpRequest request, BodyHandler<T> responseBodyHandler);
// sync. NOT used.
<T> HttpResponse<T> send(HttpRequest request, HttpResponse.BodyHandler<T> responseBodyHandler) throws IOException, InterruptedException;
}Where the type parameter T represents the body of the response which was obtained by applying the supplied responseBodyHandler.
The key difference between the two versions is that the “plain” send blocks the calling thread. If a response takes 1 minute to respond, then that is how long the calling thread will hang for. Using blocking IO is not scalable, but the reason we want the async version is to have an opportunity to practice working with CompletableFuture.
Baseline code
First, we define below the more boring methods that parse a HTML document and then extract and filter the links. We also instantiate the HttpClient instance:
Baseline code
import io.vavr.collection.HashSet; // we use functional library 'vavr' ...
import io.vavr.collection.Set; // ... for sets and linked lists.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class Crawler {
private final HttpClient httpClient =
HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_1_1)
.followRedirects(HttpClient.Redirect.NORMAL)
.build();
public Crawler() {}
// Only place/method where we call 'Jsoup' library.
// Alternatively, we could have used a regex expression.
private Set<String> extractLinks(String htmlDoc) {
Document doc = Jsoup.parse(htmlDoc);
Elements elements = doc.select("a[href]");
return HashSet.ofAll(elements).map(element -> element.attr("abs:href"));
}
// Given the set of Uris obtained from the method above,
// we parse it and filter undesirable ones
private Set<URI> parseURI(Set<String> strUris) {
return strUris // this is a 'vavr' set. But don't let distract you
.flatMap( // flatMap is a very useful ( does not exist on standard Java sets)
uriStr -> {
try {
URI uri = URI.create(uriStr);
// Below, the last two parameters set to null are the 'queryString` and 'fragment'
return HashSet.of(
new URI(uri.getScheme(), uri.getAuthority(), uri.getPath(), null, null));
} catch (Exception e) {
return HashSet.empty(); // don't fail parsing the others if one URI fails parsing
}
})
.filter(uri -> Objects.equals(uri.getScheme(), "https"))
.filter(uri -> uri.getHost() != null && !uri.getHost().isBlank())
.filter(uri -> uri.getPath().endsWith(".html") || !uri.getPath().contains("."));
}
}Above, at parseURI we ignore the query-string and fragment components of a URI.
Different fragments relate to the same HTML page:
- https://example.com/page#section1
- https://example.com/page#section2
And if we don’t ignore them, we would be crawling the same page twice, which is pointless.
Similarly, most of the times query-strings are only used to pass on tracking information:
- https://example.com/?utm_source=google&utm_campaign=summer_sale
So we ignore them as well. We will lose genuine pages when the query-string relates to pagination (e.g. https://example.com/blog?page=3) and dynamic content, but we accept that in exchange for simplicity.
Additionally, we want to crawl only though normal static HTML pages, so we filter out URIs for .pdf, .zip, .exe, .png and similar resources.
Future of a HTTP response
Next, lets define scrapeExternalLinks, where we actually make a network request using the HttpClient. This method is the source of all concurrency in the “app”.
Given a parent web-page, we make a network request for its HTML, and then extract the children URIs. We are not “crawling” yet. The snippet below issues a single HTTP request for a particular page.
public class Crawler {
private CompletableFuture<Set<URI>> scrapeExternalLinks(URI uri) {
HttpRequest req;
try {
req = HttpRequest.newBuilder(url).GET().timeout(Duration.ofSeconds(2)).build();
} catch (Exception e) {
return CompletableFuture.failedFuture(e);
}
return httpClient
.sendAsync(req, HttpResponse.BodyHandlers.ofString()) // : CompletableFuture<HttpResponse<String>>
.thenApplyAsync(res -> extractLinks(res.body())) // : CompletableFuture<Set<String>>
.thenApplyAsync(this::parseURI); // : CompletableFuture<Set<URI>>
}
public static void main(String[] args) {
CompletableFuture<Set<URI>> childrenF =
new Crawler()
.scrapeExternalLinks(URI.create("https://reddit.com/r/java"));
Set<URI> children = childrenF.join(); // fine to block, as this is the end of the program
children.forEach(System.out::println);
}
}Here we are using the thenApply – which is one of the most useful “chaining” methods on CompletableFuture’ API – to transform the raw HTTP response into the child URIs. We use the async version of it and do not specify an executor, so Java’s commonPool executor is used.
Other “chaining methods” of CompletableFuture we will use heavily throughout this example are:
- whenCompleteAsync
- thenComposeAsync
We will also develop a chaining method of our own.
Have a look at A Guide to CompletableFuture for more detail on this chaining and the API. In particular at the difference between the “async” and “sync” versions of each chaining method.
The image below illustrates the method. It is of central importance because it is where the “app” becomes concurrent.
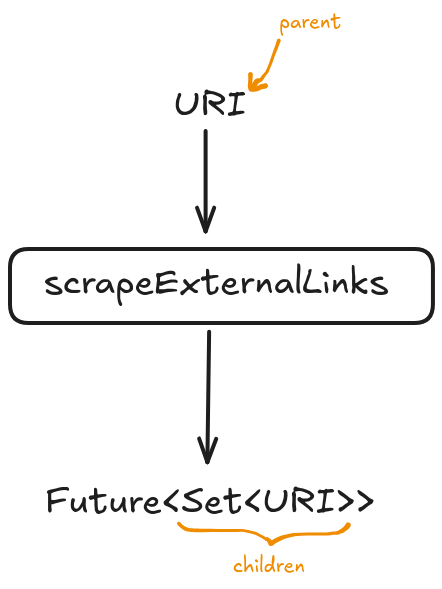
For example, crawling https://reddit.com/r/java would give us back:
https://bell-sw.com/
https://www.microsoft.com/openjdk
https://redditinc.com
https://www.reddit.com/best/communities/1/
https://reddithelp.com/hc/sections/360008917491-Account-Security
https://accounts.reddit.com/adsregister
https://www.redditinc.com/policies/privacy-policy
https://reddit.com/en-us/policies/privacy-policy
https://www.reddit.com/posts/2024/global/
https://www.azul.com/downloads/zulu/
https://www.redditinc.com
https://reddit.com/t/tarot_and_astrology/
https://reddit.com/t/oddly_satisfying/
https://developers.redhat.com/products/openjdk/download/
https://reddit.com/t/tv_news_and_discussion/
https://www.graalvm.org/downloads/
https://mail.openjdk.org/pipermail/jdk-dev/2024-October/009429.html
https://play.google.com/store/apps/details
https://reddit.com/t/funny/
https://blogs.oracle.com/java-platform-group/update-and-faq-on-the-java-se-release-cadence
https://reddit.com/t/tech_news_and_discussion/
https://www.reddit.com/best/communities/7/
https://reddit.com/t/drama_movies_and_series/
https://reddit.com/t/memes/
// <other pages>Recursion with thenCompose
This is where things get more interesting.
Since none of the children links are to hacker-news, we need to scrap the descendants as well. This means feeding each of the children to the very same scrapeExternalLinks.
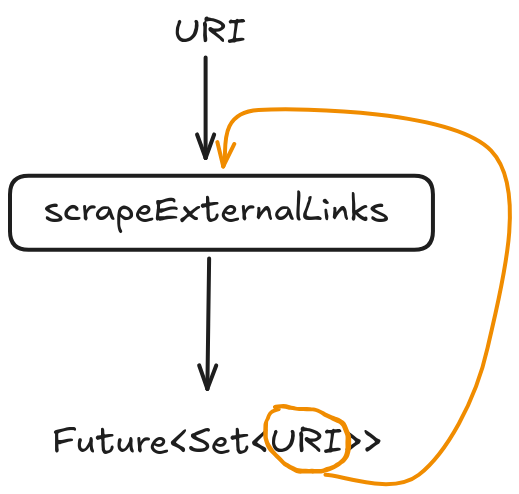
The children URIs are only available asynchronously as they are “inside the Future”. We could block the thread to wait for its completion before feeding them back, but in that case, there would be no point of using CompletableFutures altogether. This requires an async approach.
This time, thenApply is not appropriate, because the returning nested type would not be usable:
CompletableFuture<Set<CompletableFuture<Set<URI>>>> grandChildren(URI parent) {
return scrapeExternalLinks(parent)
.thenApplyAsync(children /* Set<URI> */ -> children.map(this::scrapeExternalLinks));
}We want to simplify this into a flatten CompletableFuture<Set<URI>>, representing the same data: all the grand-children links of the parent.
To obtain this flatten type, we need to “unbox” the inner future, and “unbox” the inner set. This unboxing is not trivial.
A second problem with the snippet above is that it stops at the grand-children, but we need to crawl through all the descendants.
Solving this begins by using operator thenCompose on CompletableFuture.
All we need to do is provide a lambda function that takes a set of URIs – the direct children of the parent – and returns another CompletableFuture containing the grandchildren.
Then the implementation of thenCompose will “unbox” the nested future on its own. So that is quite powerful:
CompletableFuture<Set<URI>> crawlFrom(URI parent) {
return scrapeExternalLinks(parent) //: CompletableFuture<Set<URI>>
.thenComposeAsync(
children -> { // children: Set<URI>
Set<CompletableFuture<Set<URI>>> grandChildrenNested =
children.map(this::crawlFrom); // recursive call
// how to obtain this though?
CompletableFuture<Set<URI>> grandChildrenF = ???;
return grandChildrenF;
}); // return type is 'flatten' CompletableFuture<Set<URI>>
} The problem now is that the grand-children – on lines 5/6 – are inside a set of completable futures. We need to “invert” that so that we get a CompletableFuture of a set as prescribed on line 9.
Conceptually what we need to do is create a CompletableFuture that completes once all those futures (on line 5) complete, and its value being the set-of-sets flatten together.
A good candidate to achieve this behaviour is the static method CompletableFuture.allOf.
Understanding recursion
Before that, lets take a step back and analyse what this method does, because its recursive nature makes it hard to understand.
Given a parent web-page, we are obtaining its children. Once those are known, we take each, and again obtain their children (grand-children from the parent pov), and then we take each of those, and again obtain their children, and on and on… without end.
This recursion never stops (something we need to fix), but it is the recursive nature of the approach which we need to get our heads around. At each stage (each parent), the corresponding CompletableFuture never actually completes! It depends on other CompletableFutures that themselves will depend on other CompletableFutures …. and on and on. Currently, this only ends if at some point all the web-pages have zero children, at which point everything “bubbles up”.

Heap memory
The number of pages to be downloaded grows exponentially, and every-time we create CompletebleFuture instances and chain them. These futures might live until the app terminates, so the memory required keeps increasing. Have a look at section Memory usage and metrics
That makes this approach mostly educational. An insightful example on how to leverage the power of the CompletableFuture, but not usable as a serious web crawler.
That said, you should still be able to crawl though millions of pages with on an average computer.
Flattening the Future
There are a two issues with the approach so far:
- We only obtain the descendant URIs, but what we want is the path (sequence of URIs) to a page of the destination website (e.g. hacker-news).
- We are recursing endlessly. There is no “stop condition”.
The following changes fix both issues:
class Crawler {
// configurable. e.g. 'news.ycombinator.com'
private final String destination;
CompletableFuture<List<URI>> crawlFrom(URI parent) {
return scrapeExternalLinks(parent) //: CompletableFuture<Set<URI>>
.thenComposeAsync(
children -> { // children: Set<URI>
Option<URI> finalPageOpt =
children.find(child -> child.getAuthority().contains(destination));
if (finalPageOpt.isDefined()) // the stop condition
return CompletableFuture.completedFuture(List.of(parent, finalPageOpt.get()));
// else, continues crawling
Set<CompletableFuture<List<URI>>> pathsToDestination = children.map(this::crawlFrom);
CompletableFuture<List<URI>> res = ???; // How to obtain this?
return res;
});
}
}Meaning of crawlFrom
The meaning of the method has changed. Rather than returning a set of all descendant web-pages, it now returns a list representing the sequence of web-pages connecting the parent (head of the list) to the web-page of the destination website (the last element). This is evident on lines 6, 17, and 19.
Additionally, if no such path is found, then it should return a failed future, rather than returning successful future with an empty list.
Break condition – Lines 10-14
At each iteration, we check if any of the children web-pages concern the destination website. In that case, we can stop crawling. We just return the parent and the relevant child, because that is what respects the semantics of the method.
Naturally, this “algorithm” is recursive. So the call to crawlFrom at which the break-condition was encountered will have been an inner iteration. So this future at line 14, will have to bubble up the chain. That is, the “parent iteration” will need to handle the completion of the future.
Continue crawling – Lines 17-20
If none of the children web-pages matches the one we want, we continue crawling by feeding all the children back into the crawlFrom method.
Because we start with a set of children, we obtain a set of completable futures. Each future represents a the path to the destination host (e.g. news.ycombinator.com) from the perspective of that particular child. Or, if there is no path from that child, a failed future.
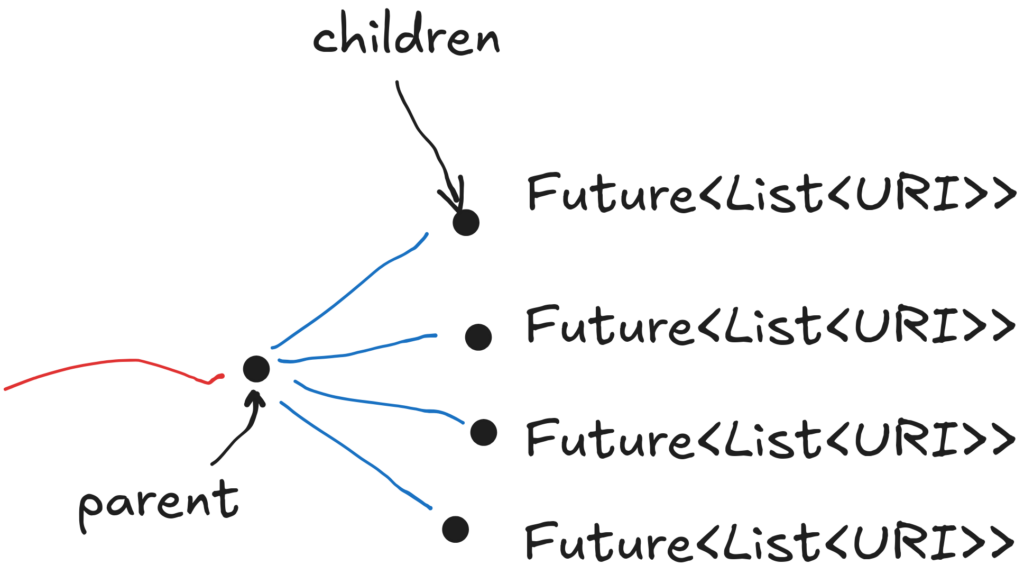
Naturally, those futures don’t complete at the same time. Each represents recursive calls down the “exploration path” of that child until the destination is found. But that might happen on the next iteration, or at the 1000th iteration, or even never stop stop crawling (and therefore the future never completes).
The hard part is how to take all those futures at line 17 and on the diagram above, and return a single one?
Combining futures
Conceptually, we want the first future that completes successfully:
- We ignore failed futures, because they represent an “exploration” which failed to reach the destination.
- If there are many successful futures, we want to return the first that finishes.
We could try and use CompletableFuture.allOf. But it violates both points above. It “waits” for the completion of all the futures. Additionally, the future returned by allOf will fail (i.e. complete exceptionally), even if one of the underlying futures also fails.
Another candidate would be CompletableFuture.anyOf. But, even though this one doesn’t wait for all underlying futures to complete, it returns the first to complete even if the that is a failed future.
(For a more detailed dive into chaining and combining futures see A Guide to CompletableFuture)
What we need is a similar version, where we take the first successful future, and ignore failed ones. Because no such method exists on the standard API, we have to create our own version:
<T> CompletableFuture<T> anySuccessOf(Set<CompletableFuture<T>> cFs) {
if (cFs.isEmpty())
return CompletableFuture.failedFuture(new IllegalArgumentException("No futures passed in."));
AtomicInteger counter = new AtomicInteger(cFs.length());
CompletableFuture<T> cfToReturn = new CompletableFuture<>();
cFs.forEach(
cF ->
cF.whenCompleteAsync(
(success, error) -> {
if (success != null) cfToReturn.complete(success);
else {
if (counter.decrementAndGet() == 0)
cfToReturn.completeExceptionally(
new CompletionException("All other futures also failed.", error));
}
}));
return cfToReturn;
}Tying everything together
Finally, we can put everything together by using anySuccessOf above to compute the successful path from the children’s perspective at line 13:
CompletableFuture<List<URI>> crawlFrom(URI parent) {
return scrapeExternalLinks(parent) //: CompletableFuture<Set<URI>>
.thenComposeAsync(
children -> { // children: Set<URI>
Option<URI> finalPageOpt =
children.find(child -> child.getAuthority().contains(destination));
if (finalPageOpt.isDefined()) // the stop condition
return CompletableFuture.completedFuture(List.of(parent, finalPageOpt.get()));
// else, continues crawling
CompletableFuture<List<URI>> successPath =
anySuccessOf(children.map(this::crawlFrom));
CompletableFuture<List<URI>> res =
successPath.thenApplyAsync(thePath -> thePath.prepend(parent));
return res;
});
}Importantly, notice that because successPath represents the successful path from the perspective of one of its children, we cannot return that future, as it would be inconsistent with the definition/semantics of the method which specifies that the list returned represents the path from the parent. For this reason, at line 16, we need to transform that future with an extra operation that prepends the parent to the list.
Further improvements
The hard part is done. This is the core behaviour of the crawler. But some refinements are needed:
- Concurrency Limiter: We have no control over how fast we issue HTTP requests.
- Don’t revisit pages: We are revisiting the same page multiple times.
Improving the crawler
Concurrency limiter
The problem
We have no control over how fast the HTTP requests are made.
As soon as a web-page is scrapped and its links parsed, it immediately launches requests for those child-links. This is a problem because the number of links grows exponentially with the number of “levels”: If each URI contains ten children, then there are 1000 grand-grand-children. On the 5th iteration there would be 100k children, and on the 8th iteration, 10 million.
This leads to the Internet connection becoming unusable for anything else, as all bandwidth is used for requests.
On top of that, each page would be downloaded very slowly, because there would be so many others competing for bandwidth. This would likely trigger the timeout configured for the HttpClient instance.
The Solution
Rather than implementing a rate limiter, where we throttle the number of requests per second, its easier to implement a concurrency limiter which restricts the amount of live concurrent HTTP requests.
These two approaches are related, somewhat linearly. So by reducing concurrency, we are able to make things go slower and prevent the app from gobbling the internet bandwidth.
In either case, it requires deciding what to do with the excess requests. For practising our async muscles, rather than discarding them, its more interesting to buffer them into a queue, to be picked up later.
This queue will growth indefinitely, taking ever more memory. But as mentioned before, the app already has this limitation regardless.
The method responsible for making the HTTP requests is scrapeExternalLinks. We need a way to call this method only when the number of concurrent HTTP requests is below a configured maximum.
Because the requests are completely concurrent, there must me some shared state on which we can synchronise. This can be done with an AtomicInteger to keep track on the number of HTTP requests which are live.
Then, when a new web-page (i.e. URI) needs to be scrapped, we first check the current concurrency. If its lower than the maximum allowed, we call scrapeExternalLinks, otherwise we save it in the queue to be picked up later.
public class Crawler {
private final AtomicInteger concurrency = new AtomicInteger(0);
private final ConcurrentLinkedQueue<CompletableFuture<Void>> queueFutures =
new ConcurrentLinkedQueue<>();
private final int maxConcurrency; // configurable
private void returnPermission() {
CompletableFuture<Void> cF = queueFutures.poll();
if (cF != null) cF.complete(null);
else concurrency.getAndDecrement();
}
<V> CompletableFuture<V> getPermission(Supplier<CompletableFuture<V>> cFToRun) {
int current = concurrency.get();
if (current < maxConcurrency) {
if (!concurrency.compareAndSet(current, current + 1)) getPermission(cFToRun);
return cFToRun.get().whenCompleteAsync((ignoredL, ignoredR) -> returnPermission());
}
CompletableFuture<Void> cF = new CompletableFuture<>();
queueFutures.offer(cF);
return cF.thenComposeAsync(ignored -> cFToRun.get())
.whenCompleteAsync((ignoredL, ignoredR) -> returnPermission());
}
CompletableFuture<List<URI>> crawlFrom(URI parent) {
return getPermission(() -> scrapeExternalLinks(parent))
.thenComposeAsync(
children ->
children
.find(child -> child.getAuthority().contains(destination))
.fold(
() ->
anySuccessOf(children.map(this::crawlFrom))
.thenApplyAsync(successPath -> successPath.prepend(parent)),
destinationURI ->
CompletableFuture.completedFuture(List.of(parent, destinationURI))));
}
// remaining code
}Don’t revisit pages
We also don’t want to wast resources – particularly network bandwidth – visiting the same page more than once. After we scrape a URI, we don’t need to do it again.
This currently happens because the same page can naturally be reached from multiple distinct pages.
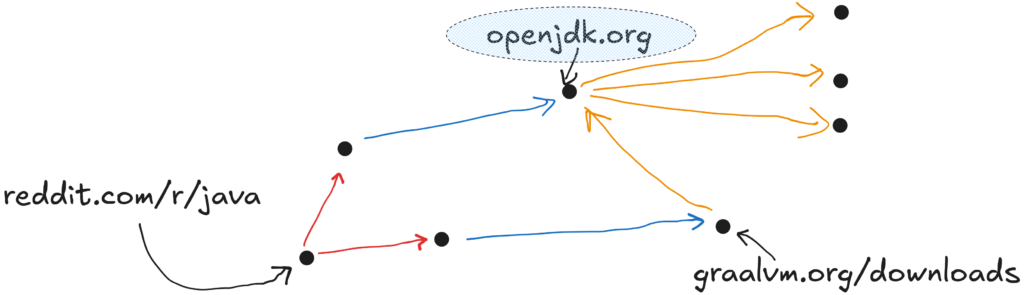
Above, after scrapping graalvm.org/downloads, we need to remove openjdk.org from the set of children to recurse to, because it has already been visited by “another future”. This also prevents revisiting all the children of the latter.
As before, because the app is highly concurrent, we need to have a class-level mechanism that allows all futures to synchronise on which pages have been visited and also update the visited pages to add new ones.
This can be achieved by a (thread-safe) concurrent set. From the list of all children scrapped from a parent web-page, we filter out those that have been visited already. Then we add the rest to the thread-safe set and continue processing:
public class Crawler {
private final java.util.Set<URI> urisSeen =
Collections.newSetFromMap(new ConcurrentHashMap<>());
public CompletableFuture<List<URI>> crawlFrom(URI parent) {
return getPermission(() -> scrapeExternalLinks(parent))
.thenApplyAsync(children -> children.filter(uri -> !urisSeen.contains(uri)))
.whenCompleteAsync((childLinks, ignored) -> childLinks.forEach(urisSeen::add))
.thenComposeAsync(
children ->
children
.find(child -> child.getAuthority().contains(destination))
.fold(
() ->
anySuccessOf(children.map(this::crawlFrom))
.thenApplyAsync(successPath -> successPath.prepend(parent)),
destinationURI ->
CompletableFuture.completedFuture(List.of(parent, destinationURI))));
}
// remaining code
}The immutable/functional API of the Set in vavr library makes the filter operation very clean and succinct, but again the same could have been done with a “normal” java Set.
Memory usage and metrics
The aim of this post is to serve as an interesting and insightful example on how to use the CompletableFuture and async programming because most other articles out-there provide only really trivial examples.
But, as a serious crawler, this approach is limited since we keep everything in memory.
As mentioned before, the number of pages grows exponentially with every iteration. Because we find new pages faster than they are downloaded, the buffer on the queue grows without bound.
Furthermore, as we crawl, we keep creating a lot of CompletableFutures. Many of these futures will live for the entire live-time of the app. On top of that, we chain these futures with lambdas that will be stored in memory as well.
Non-surprisingly, if you run the app for long enough, you will exhaust the heap available. That said, I was still able to crawl through millions of pages with a few GB of heap.
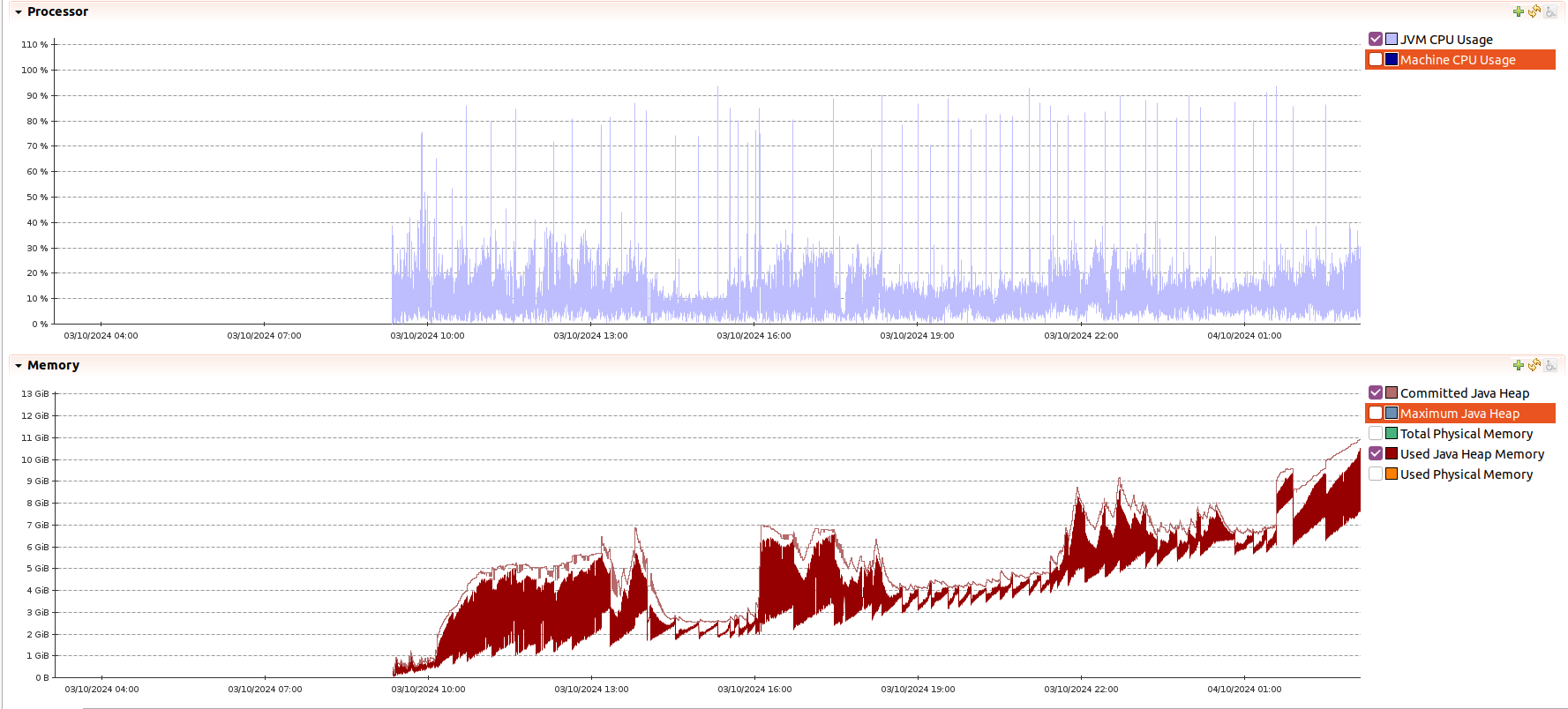
reddit.com/r/java and with never finding the destination (this website :/)Much more could be analysed, but I don’t want to make this post to big. If you have any questions, please ask below.
Look at the code ( ~150 pages) on github.
Thank you for the post.
p.s.:
vavr can mostly replace by modern stream API.
The only part is the “fold” part in the method crawlFrom
Thank you for the support!
Good suggestion, but we will have to verify the “thread-safe guarantees” of the stream API are suitable first.
We need to be concerned about that because every time we “chain” a CompletableFuture, the operation will take place in a different thread.
In the case of vavr collections, they are immutable, which effectively makes them thread-safe by default.
Hello! Thank you for a great example of use CompletableFuture API.
Can I translate your post on russian for my students? (I’m a university lecture)
Thank you for your kind words! I’d be happy for you to translate my post into Russian. Please include a link back to my website as the original source—I’d appreciate it!
Thanks again, and I hope the translation is helpful to your students!
I noticed Understanding recursion section image is not loading.
Can you refresh the browser cache and retry please.
I tested on desktop and smart-phone and should be working.
let me know.
Hello,
I’m really enjoying your articles, truly one of the best concurrency deep dives for java. Bookmarked the page and looking forward for the articles that are under construction.
Why many of these futures will live for the entire live-time of the app? Won’t the GC clean them?
Thank you! That means a lot.
The GC won’t clean them because it shouldn’t. This is because there are new recursions on top of those futures.
If you have nytimes.com –> reddit.com –> youtube.com –> …
The future of nytimes.com can’t be GCed because the subsequent searches reference it.
We could improve the code so that this doesn’t happen, but it would make it more complex and being simple was better for educational purposes.
Hi,
I enjoyed your article as much as others however, there is one thing I do not understand.
In the `Concurrency Limiter` section code snippet, you are incrementing concurrency counter only if the current < maxConcurrency (line 8), which you would subsequently decrement when the code on line 9 is executed. But you also decrement the counter on line 24, and it is not clear to me where that permission is acquired.
Would not it cause the permission leak?
Probably, the counter should be incremented unconditionally, and the check current < maxConcurrency is needed only to decide whether to execute supplier's future immediately or place it into the queue. Apologies, if I missed something obvious.
Thank you again for the article.